最新的开源项目 – 跨端技术Aether
2025-4-29
一、前沿
随着2023.11月份KMP的第一个stable版本发布,KMP相当于迈入了一个新的台阶,做为从Native到Flutter以及KMP的见证者,在多端渲染和一致性上,这么多年业内工程师做了很多努力,早期的weex,DynamicX,后来的flutter,蚂蚁的cube/鸟巢,字节自己的lynx,无论哪一种哪家都希望能从一套技术栈统一掉平台的差异,同时兼具动态化的能力,但是都没有根本的解决渲染损耗的问题。随着KMP的发布,至少对于Android侧是几乎无损的,给我带来非常大的欣喜,我决定去探索这门新的方向会给客户端带来什么?以及记录下我对KMP对行业的影响和思考。
笔者从2024年开始研究KMP的引入会对原有终端生态带来哪些影响,并且长期关注该技术如何能跟现有业务做一个联动,探索出一条不一样的技术路径,并坚信它可以对现有跨端能力进行一轮重构,目前基本链路已经跑通,起名“Aether”,物理学里认为它类似于光波声波这种介质传播,寓意能够兼具开放和云端传递动态的能力。
二、Aether的优势和劣势
Aether的初心是通过建立一个Android程序员不要再使用不优雅的js来实现动态化能力,我们希望能够提供完整的一套基于Kotlin的动态化的解决方案。我的思考是基于当前的KMP天然的跨端基础上,寻找到一种实现动态化的能力方案,对于Android工程师抛弃不优雅的js语法,真正意义上写kotlin就能完成动态化的能力。基于这个背景我开始了调研,过程中不断的尝试,攻克了一个又一个难点,完成初步目标。
2.1 核心目标
- 保证通用性,能够保证KMP的跨能能力
- 门槛低:足够的低成本上手:不希望对新手有很大的上手成本
- 丰富的调试工具:希望能够在开发Aether卡片的时候有很多工具可以使用
- 适用性:不能有很大的包大小的引入
2.2 技术选型
1. 利用JS引擎
JS局限性:Native测本身是具备解析js的环境,但是经过技术方案审慎评估,我们发现Native端基于JS动态执行环境构建DSL生成机制的技术路径,虽然可实现动态化但是存在显著的局限性,具体而言,该方案通过运行时动态构建包含页面逻辑和事件绑定的DSL,技术KMP进行组件化渲染,其核心实现原理虽然与RN技术存在相似性,但是本质上深度整合了KMP的框架体系。
从实现效果来看,该架构在动态化支持方面具备可行性,但是存在关键性的制约因素:首先,技术实现层面需要严格对其KMP的框架规范,导致js承担大量的适配工作,造成研发成本较高且开发体验折损,其次,技术栈依赖js的执行机制,在运行时频繁的触发KOTLIN与JS的语言通信(IPC),产生不可忽略的性能折损,这也是Weex,Lynx局限性,难以满足我们对高性能的要求,更为关键的是该方案强制开发者将现有的Kotlin的开发体系迁移至JS体系,导致Kotlin工具链的完整兼容性失效,这与我们的低成本上手背道而驰。
综上,从技术路径可行性、性能、以及对新手友好程度等三个维度存在系统性的挑战,我认为这不是最优解,我们尝试探索更多范式。
2. 生成Kotlin dsl
我们以平台的官方语音kotlin语法作为输入,通过转换层完整提取语义信息生成DSL,集合Kolin与KMP映射体系和基础逻辑运行时,实现纯Kolin环境下的组建渲染和交互闭环。
技术实现层面,该方案采用了Kotlin官方的KotlinCompiler库(已广泛应用在代码的格式化、java转Kotlin等工具链),其中标准化的API对Kotlin源码级别进行文件级别的AST抽象语法树构建,AST的数据结构系统化承载了代码的完整语义,为DSL的生成提供了结构化输入,整套编译阶段可以在容器内部完成也支持离线完成(优化加载速度),最终生成的这套DSL驱动KMP的渲染链路。
此架构设计具备三种技术价值:完成的保留了Kotlin的工具链和语法糖,消除了跨平台的适配成本、通过静态映射实现逻辑动态化、避免依赖JS引擎带来的运行时开销、最终在开发体验、性能指标和平台兼容性上都达到了工程化的最优解。
2.2 项目架构
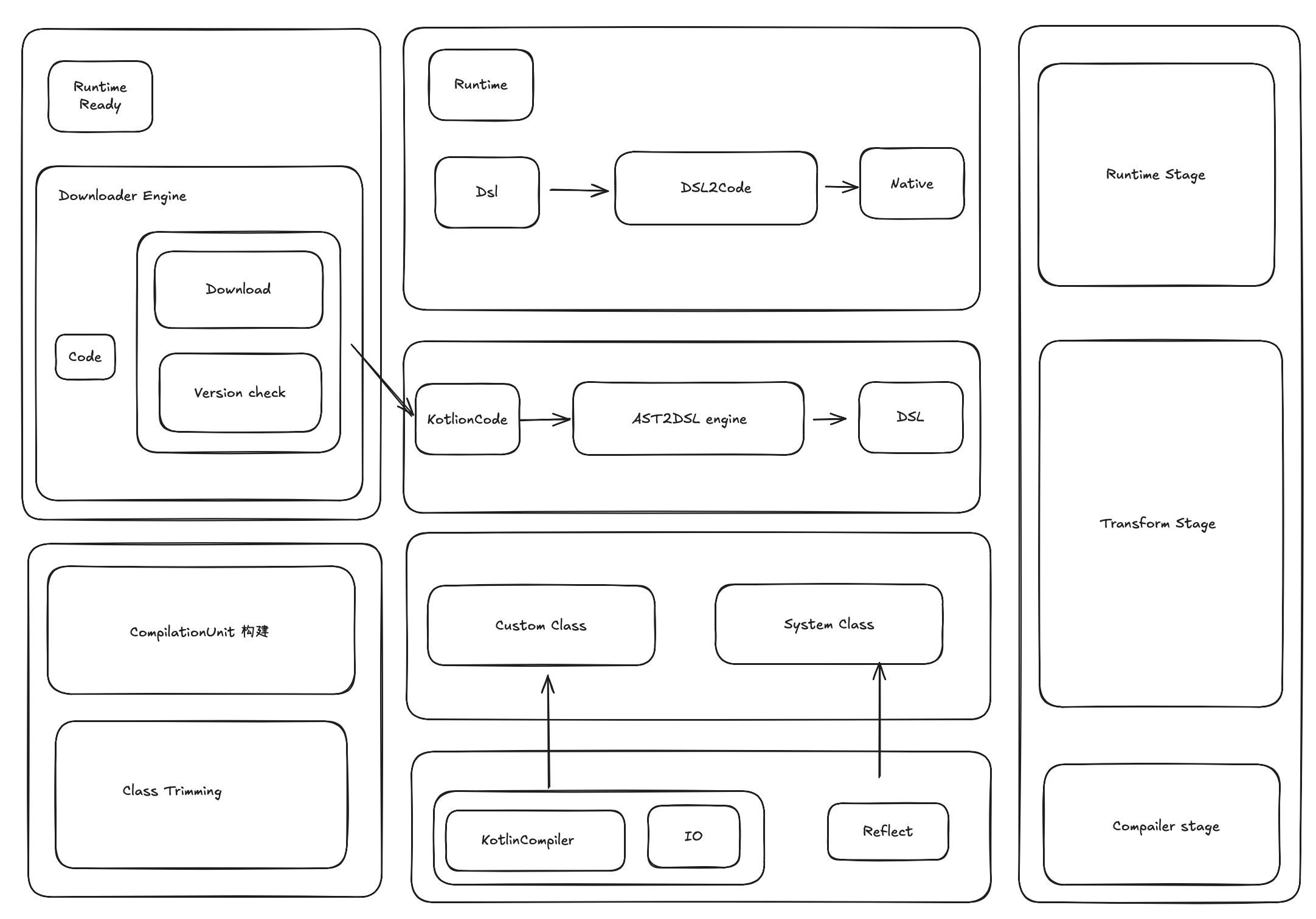 最下面的部分是编译依赖
最下面的部分是编译依赖- 中间是转换阶段
- 最上面是核心的runtime,runtime核心的是做一个类似于虚拟机的栈,保证所有的转换后的DSL映射后的对应数据,模拟成系统的栈结构。
三、困难
1. AST转换难点以及运行原理
AST意思是就是一个抽象的语法树,Kotlin的语法树与其他语言类似,但是还是存在差异,在Kotlin里,“org.jetbrains.kotlin.lexer.tokens”包含了所有的token。AST通过compiler解析语法树里的各个token值完成语法树的解析。
举个例子
object DemoFunctionExpress {
/** * result =10 * result2 =10 * index = 5 */
fun test2(index: Int, item: String): Int {
val a = 2
val b = 2 + index
return a * b
}
}
如果不加以精简它是一个非常庞大的一个数据结构。
精简后。最后它的机构是类似于这种
KtFile (name: DemoFunctionExpress)
│
└── KtObjectDeclaration (name: DemoFunctionExpress)
│
└── KtNamedFunction (name: test2, parameters: [index: Int, item: String], returnType: Int)
│
├── KtParameter (name: index, type: Int)
├── KtParameter (name: item, type: String)
│
├── KtBlockExpression
│ │
│ ├── KtValVarKeyword (keyword: val)
│ ├── KtNameIdentifier (name: a)
│ ├── KtConstantExpression (value: 2)
│ │
│ ├── KtValVarKeyword (keyword: val)
│ ├── KtNameIdentifier (name: b)
│ ├── KtBinaryExpression (operator: +)
│ ├── KtConstantExpression (value: 2)
│ ├── KtNameReferenceExpression (name: index)
│
│ └── KtReturnExpression
│ └── KtBinaryExpression (operator: *)
│ ├── KtNameReferenceExpression (name: a)
│ ├── KtNameReferenceExpression (name: b)
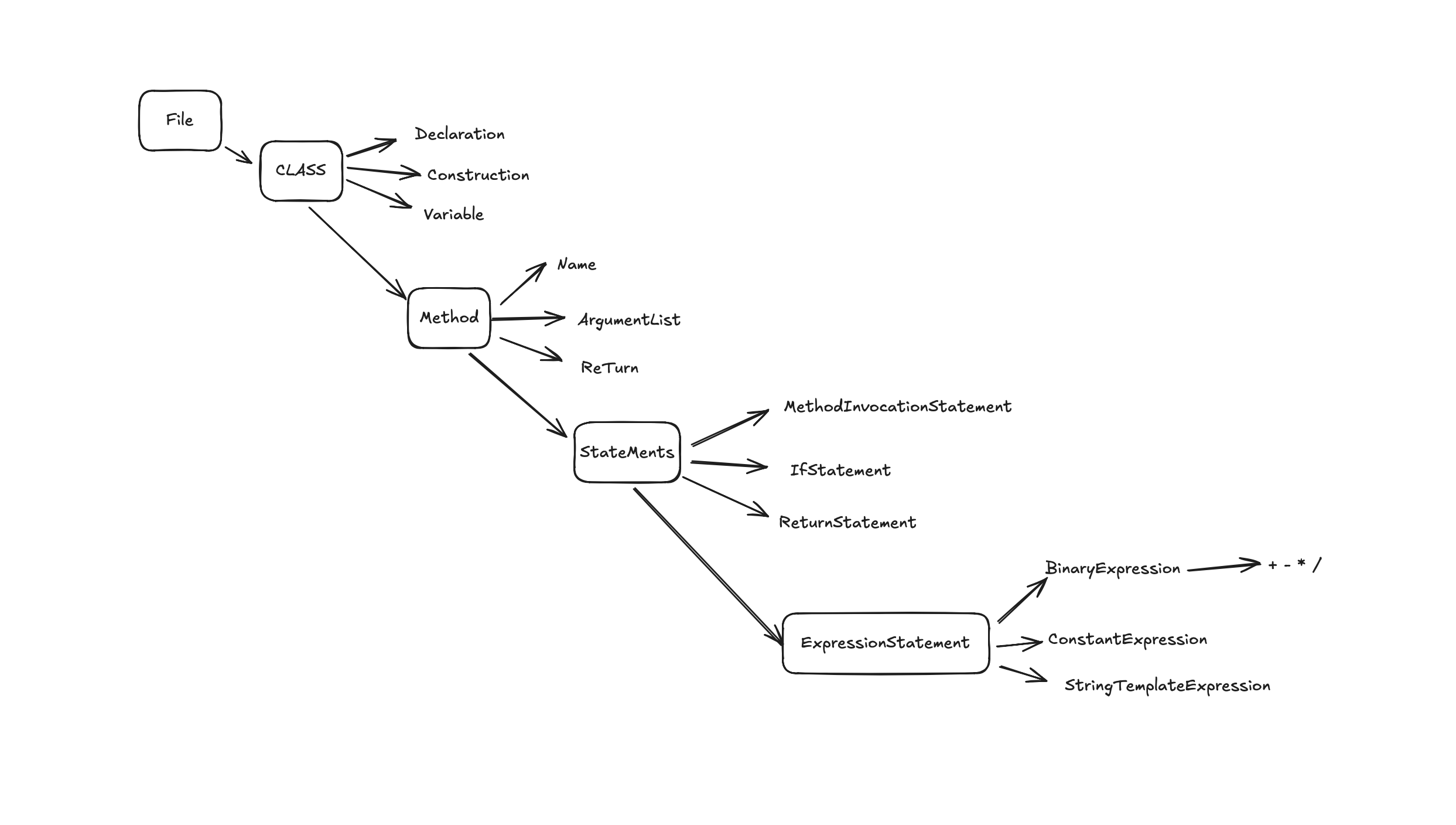
这个结构最外层就是一个progrem代表一个最小的程序单元,内层是嵌套一个KtObjectDeclaration,它表示一个函数的声明,再内部就是一个表达式和一些参数的声明,这个表达式最后其实就是一个将Kotlin的源码进行json化的一个转换。
生成上面的结构我们是依赖于KotlinCoreEnvirment的Visitor来进行解析,但是这个类的访问节点会遍历很多,所以我们我们需要对其进行精简,
举个例子,下面是一个二元运算的一个节点。
override fun visitBinaryExpression(
expression: KtBinaryExpression, data: Void?): Map<String, Any?>? {
println("Visiting binary expression: ${expression.text}")
super.visitBinaryExpression(expression, data)
return mapOf(
"type" to "BinaryExpression",
"name" to expression.name,
"operator" to (expression.operationToken as KtSingleValueToken).value,
"left" to visitNode(expression.left, data),
"right" to visitNode(expression.right, data),
"node" to expression,
)
}
加载流程
当我们想要去加载上述的方法的时候的时候首先我们会将原文件加载到内存里,作为解释器的输入。
val test2 = runtime.invoke("test2", mutableListOf(5))
这一步我们是将AST转成DSL,然后我们会去遍历这个AST对应的所有的节点,然后精简成我们需要的DSL加载到内存里,这一步引擎会给他一个自定义的方法名并且与映射的方法产生一一对应的关系

它的执行流程简化来说可以是一个虚拟机的执行过程
- 在堆栈上查找名称为test2的方法
- 将参数分别压栈
- 遍历方法在是否在本单元内部->相邻类->系统类
- 找到后分别执行,退栈
- 返回结果
上述案例仅展示了 DSL 体系中的基础场景片段,实际应用需处理更复杂的 多维度逻辑嵌套,典型场景包括但不限于:
- 多层循环结构中的集合操作(如
O(n²)级联flatMap与状态化reduce的复合逻辑) - 异步回调链中的高阶条件分支
- 动态上下文依赖的 AST 节点生成(基于运行时元数据的子树构建)
受限于技术文档篇幅,本文未展开具体业务实现细节,但其核心机制具有一致性:
- AST 增强型描述协议:在标准抽象语法树构建阶段,注入 上下文感知处理器(Context-Aware Processor)
- 结构化数据组装:将转换后生成的 异构 Map 节点(Typed Map Node)按原始 AST 拓扑结构进行 递归归并(Recursive Merge),确保数据层级与源结构严格同构
- 工业级序列化方案:通过 预编译型 JSON 序列化组件实现 AST 中间表示到标准化 JSON 的高性能转换,可以提高加载速度,可以作为优化项目。
当我输入5
回看上面的方法
object DemoFunctionExpress {
/** * result =10 * result2 =10 * index = 5 */
fun test2(index: Int, item: String): Int {
val a = 2
val b = 2 + index
return a * b
}
}
输出结果
val test2 = runtime.invoke("test2", mutableListOf(5,"a"))
System.out.println("动态化引擎输出结果:" + test2)
上述只是一个简单的数据处理,实际企业级的应用不可能是是这么简单的逻辑处理,我们可能还有自定义的加载类或者使用系统类,如何去保证这类能够完全的动态化呢?
apply方法
需要针对静态方法和非静态方法分别处理
fun apply(
method: AstMethod,
positionalArguments: List<Any?>,
namedArguments: Map<String, Any?>?
): Any? {
if (method.isStatic) {
xxxx
} else {
xxxx
throw IllegalStateException("error instance")
}
return null
}
}
静态方法可以直接使用方法名压栈处理
fun scopedInvoke(
parameters: List<_ParameterImpl>?,
positionalArguments: List<Any?>,
namedArguments: Map<String, Any?>?,
invoke: (List<Any?>, Map<String, Any?>?) -> Any?): Any? {
val programStack = context.get<ProgramStack>(ProgramStack::class.java) ?: return null
programStack.push(name = "parameters scope")
parameters?.forEachIndexed { index, parameter ->
if (parameter.isNamed) {
programStack.putVariable(parameter.simpleName,namedArguments?.get(parameter.simpleName))} else { programStack.putVariable( parameter.simpleName, positionalArguments.getOrNull(index))}}
val result = invoke(positionalArguments, namedArguments)
programStack.pop()
return result }
}
}
如果非静态方法,根据类的名称分别从相对路径自定义类或者系统类去加载对应的对象并且压栈
自定义类
对于自定义类,我们通过模拟类系统存储符号信息,在解析时将Kotlin的原始文件里的节点转换为可处理对象:属性声明转为Variable类型,方法声明转为不同类型的Function类型。
如果是相对路径重新生成对应的元信息node
if (newNode != null) {
if (!dependencies.contains(newNode)) {
dependencies.add(newNode)
_visitNode(newEntity, dependencies, newNode)
}
} else {
//反射
}
在获取方法的时候通过加载刚刚自定义类的元数据完成
fun getClass(className: String): AstClass? {
return context.run(
name = "AstRuntime",
body = {
_program?.getClass(className)
},
overrides = mapOf(
ProgramStack::class.java to { programStack },
AstRuntime::class.java to { this }
)
) as AstClass?
}
fun getClass(className: String, recursive: Boolean = true): AstClass? {
//xxx
dependencies.forEach {
it.getClass(className, recursive = false)?.let { clazz -> return clazz }
}
return null
}
对于系统方法
最简单的就是反射传入类的方法和路径,精简反射的类的信息,通过getClass去构建一套基于系统的元数据结构。
经过层层拆解,最终还原一个精简版本的数据结构,用户下一步的处理
Scope上下文:
Scope 本质上承担着上下文环境的角色。当解释器对每个方法或表达式进行求值时,必须接收一个由外部传递的 Scope 参数作为执行基础。这种上下文对象具有链式传递特性:当前语句执行完成后,其可能修改过的 Scope 状态会成为下一条语句执行的输入参数。所以这里需要有一个跨线程的上下文,使用ThreadLocal维护,通过 Scope 的引用机制获取其存储位置,这种设计不仅支持数据属性的跨语句存取,还能实现方法定义的动态调用——包括方法内部嵌套调用其他已注册方法的场景。正是基于这种可传递、可扩展的上下文容器机制,系统才具备了处理用户自定义方法及其内部复杂逻辑的能力。
object AppContextManager {
private val contextHolder = ThreadLocal.withInitial { AppContext(null, "ROOT", emptyMap(), emptyMap()) }
// xxx
val context: AppContext get() = contextHolder.get()
// 设置当前线程的 AppContext
fun set(context: AppContext) {
contextHolder.set(context)
}
fun get() :AppContext{
return context
}
// 移除当前线程的 AppContext
fun removeContext() {
contextHolder.remove()
}
}
context.run(
name = " instance scope", body = {
AstMethod.apply2(
method,
positionalArguments = mutableListOf(),
namedArguments = mutableMapOf()
)
}, overrides = overrides
)
Card(
elevation = CardDefaults.cardElevation(4.dp),
modifier = Modifier.fillMaxWidth()
) {
Column(modifier = Modifier.padding(16.dp)) {
Text(
text = title,
style = MaterialTheme.typography.headlineSmall,
color = MaterialTheme.colorScheme.primary
)
Spacer(modifier = Modifier.height(4.dp))
Text(
text = content,
style = MaterialTheme.typography.bodyMedium,
color = MaterialTheme.colorScheme.secondary
)
}
}
它的结构简化下来就是如下样式,如果生成对应DSL更为庞大,这里就不展示了。
Compose Program ├── Composable Function: GreetingScreen ├── Composable Function: MessageCard │ ├── Card 容器 │ │ ├── elevation 属性 │ │ └── Column 布局 │ │ ├── Text (标题) │ │ │ ├── typography 样式 │ │ │ └── color 颜色 │ │ ├── Spacer │ │ └── Text (内容)
简化流程:每一个组件都是对应的一个特定的语法树,语法树的解析,以来上文说的递归使用上面说的动态反射机制就能够还原这些View,
四、挑战
- 工作量巨大,需要保持耐心,笔者在业余时间进行探索,几乎已经全部时间进行投入。
- 项目较为复杂,核心链路虽然跑通了,但是一些复杂的语法还未支持,需要保持一定耐心去兼容,之所以开源出来也是希望依赖于社区同学一起投入进来。
- 因为牵扯到AST和DSL的转换和解析执行虚拟机的加载,对于排查问题有一定的门槛,边界异常逻辑处理需要后继者更为注意。
五、未来支撑的生态
虽然Aether的设计理念和效率上都有很大的技术创新和亮点,能够做到对于90%以上场景媲美原生,做到了真正的兼容性能与跨端和动态化的能力,并且整个链路最小单元已经跑通了,但是目前还是依赖于笔者一个人去开发,还缺乏一些脚手架,希望能够涵盖研发、调试、监控、测试、一体的建设。大图如下
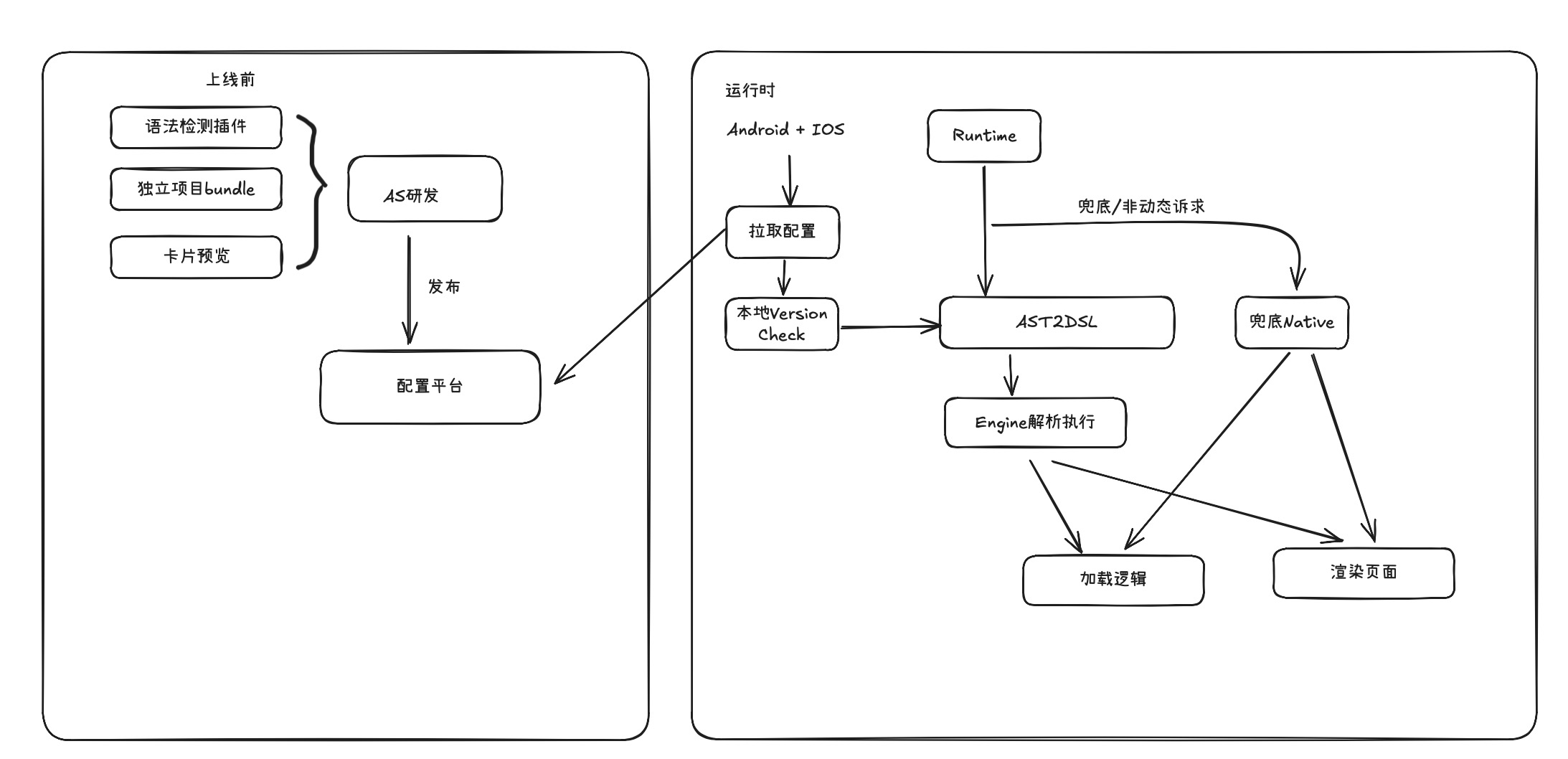
Aether 业内首次创新性基于AST + Runtime 构建KMP的动态化方案,实现逻辑页面动态下发,全流程覆盖开发至运维。提升发版效率与热修复能力,有效缓解KMP缺失的动态化,可大范围的推动Android KMP的生态发展,甚至可以革命掉现有Lynx和Weex的生态,但因为个人精力有限,还有很多工程化的能力需要建设,期待社区一起未来后续将强化复杂语法支持与生态建设,降低开发成本、优化体验并扩大业务覆盖;推进大前端融合,实现跨终端一致性体验。
 沪ICP备2025124802号-1
沪ICP备2025124802号-1
大佬