前言
随着移动互联网的快速发展,用户对网络体验的要求越来越高。然而,在实际应用中,我们经常遇到各种网络性能问题:页面加载缓慢、应用响应迟滞、连接超时等。本文将通过五个典型案例,深度剖析现代网络协议栈中的关键问题,并提供系统性的优化方案。
目录
- 网络接口基础知识
- 案例一:IPv6双栈导致的上网缓慢问题
- 案例二:TCP时间戳乱序引发的连接异常
- 案例三:移动网络环境下的TCP重传超时问题
- 案例四:双带WIFI+蜂窝三网并发,打游戏依然卡顿
- 案例五:Wifi与蓝牙公用频率波段
- 根本解决方案:QUIC协议的优势
网络接口基础知识
在进行网络问题排查之前,首先需要了解系统中各种网络接口的作用:
macOS 系统网络接口详解
| 接口名称 |
功能描述 |
使用场景 |
| en0 |
主要以太网或Wi-Fi接口 |
互联网连接的主要通道 |
| awdl0 |
Apple无线直接链路接口 |
AirDrop等苹果服务 |
| llw0 |
低功耗蓝牙接口 |
蓝牙设备通信 |
| utun0-utun3 |
虚拟隧道接口 |
VPN连接 |
| AX88179B: en6 |
USB以太网适配器 |
有线网络扩展 |
| ppp0 |
点对点协议接口 |
PPPoE拨号连接 |
| lo0 |
环回接口 |
本机内部通信 |
选择正确的监控接口
对于大多数网络问题排查,**en0(Wi-Fi接口)**是最常用的监控目标。如果使用有线连接,则需要选择对应的以太网接口进行分析。
案例一:IPv6双栈导致的上网缓慢问题
问题现象
反馈网页打开速度异常缓慢,但是能成功,通过抓包分析发现以下现象:
$ curl -v http://www.google.com
* Host www.google.com:80 was resolved.
* IPv6: 2001::1 * IPv4: 31.13.88.26
* Trying 31.13.88.26:80... * Trying [2001::1]:80...
* Immediate connect fail for 2001::1: Network is unreachable
模拟真实的日志信息如下:
resolving www.google.com(www.google.com)……fcbd:de01:fe:1108::1,11.8.9.202
技术原理分析
IPv6/IPv4双栈机制
现代网络基础设施普遍采用IPv6/IPv4双栈配置:
- DNS解析行为:域名解析时同时返回IPv6(AAAA记录)和IPv4(A记录)地址
- 连接优先级:客户端通常优先尝试IPv6连接
- 降级机制:IPv6连接失败后,降级到IPv4连接
问题根源
许多网站在注册DNS记录时声明支持IPv6,但实际网络基础设施并未完全支持IPv6路由,导致:
- IPv6连接请求超时(通常需要等待75秒)
- 用户体验表现为”网页打开很慢”
- 应用程序如果没有合理的降级策略,可能直接失败
系统级优化方案
1. 操作系统层面监控
实施IPv6连接质量监控机制:
# 检测IPv6连通性
ping6 -c 3 2001:4860:4860::8888
# 监控TCP SYN成功率
ss -s | grep -E "(ipv6|ipv4)"
2. DNS解析策略优化
根据网络环境动态调整DNS响应:
# 伪代码示例
def optimize_dns_response(domain, client_network):
ipv6_success_rate = monitor_ipv6_connectivity()
if ipv6_success_rate < 0.8: # 成功率低于80%
return get_ipv4_only_records(domain)
else:
return get_dual_stack_records(domain)
3. 应用层降级策略
应用程序应实现智能连接策略:
import asyncio
import socket
import concurrent.futures
class DualStackConnector:
def __init__(self, timeout=5):
self.timeout = timeout
async def connect_with_fallback(self, hostname, port):
"""并行尝试IPv6和IPv4连接,使用最快的"""
loop = asyncio.get_event_loop()
# 创建连接任务
ipv6_task = self._create_connection_task(hostname, port, socket.AF_INET6)
ipv4_task = self._create_connection_task(hostname, port, socket.AF_INET)
try:
# 使用 wait_for 实现快速降级
done, pending = await asyncio.wait(
[ipv6_task, ipv4_task],
return_when=asyncio.FIRST_COMPLETED,
timeout=self.timeout
)
# 取消未完成的任务
for task in pending:
task.cancel()
# 返回第一个成功的连接
for task in done:
if not task.exception():
return task.result()
# 如果首选连接失败,等待剩余连接
if pending:
result = await asyncio.gather(*pending, return_exceptions=True)
for conn in result:
if not isinstance(conn, Exception):
return conn
except asyncio.TimeoutError:
pass
raise ConnectionError("Both IPv4 and IPv6 connections failed")
async def _create_connection_task(self, hostname, port, family):
"""创建指定协议族的连接任务"""
try:
sock = socket.socket(family, socket.SOCK_STREAM)
sock.setblocking(False)
# 获取地址信息
addr_info = socket.getaddrinfo(hostname, port, family, socket.SOCK_STREAM)
if not addr_info:
raise ConnectionError(f"No address found for {hostname}")
addr = addr_info[0][4]
# 异步连接
await asyncio.get_event_loop().sock_connect(sock, addr)
return sock
except Exception as e:
if 'sock' in locals():
sock.close()
raise e
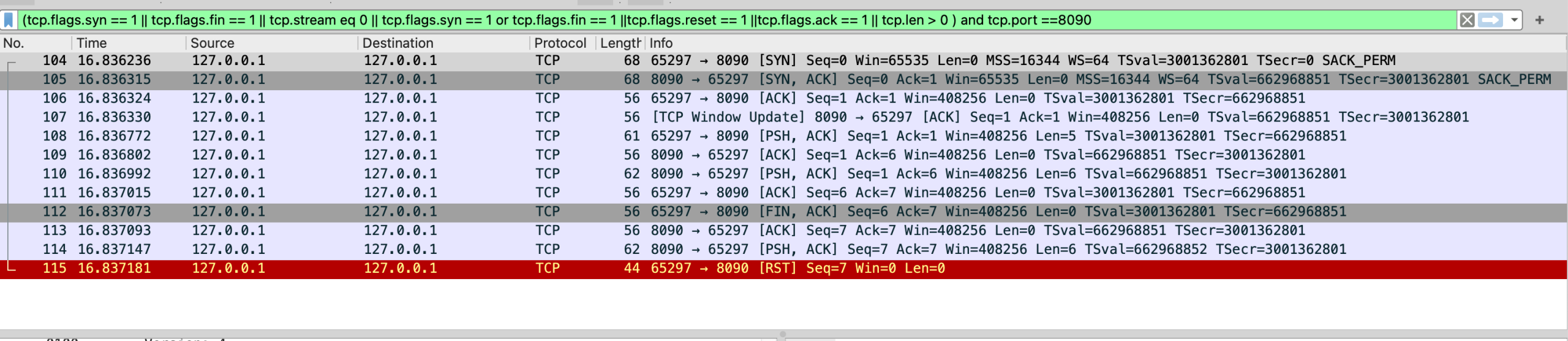
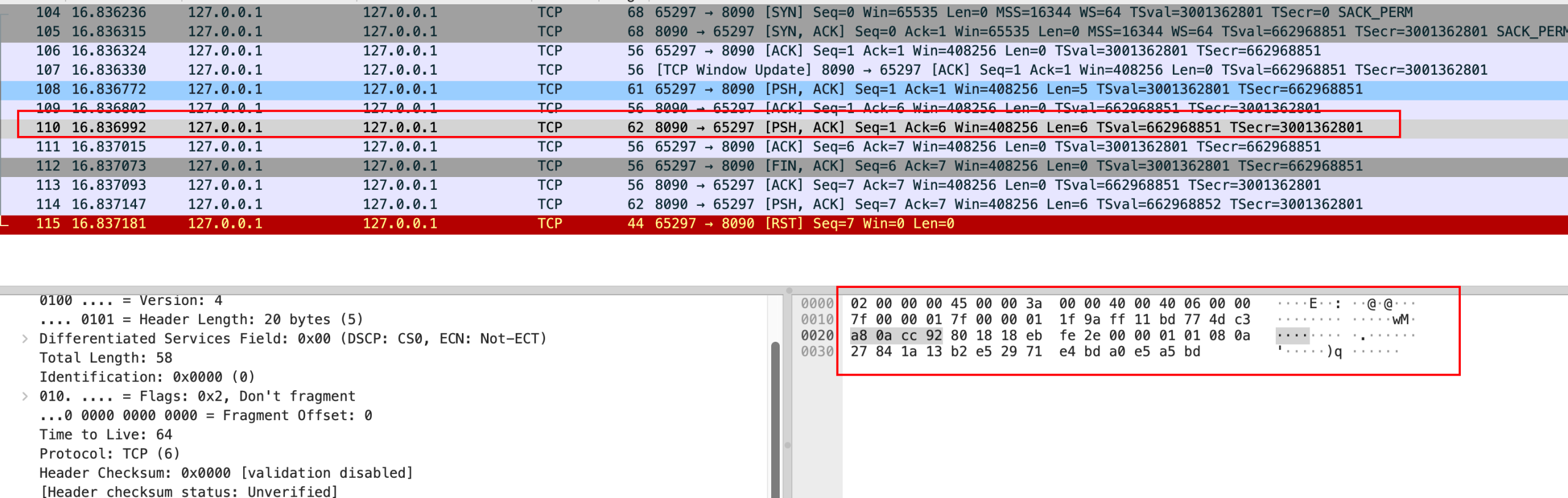
案例二:TCP时间戳乱序引发的连接异常
问题现象
用户反馈在相同WiFi环境下,手机无法上网,但电脑连接正常。通过抓包分析发现:
- 手机发送的TCP SYN包能到达路由器
- 路由器不回应SYN/ACK,连接建立失败
- TCP时间戳出现异常乱序现象
TCP时间戳机制详解
时间戳的作用
TCP时间戳选项(RFC 7323)主要用于:
- RTT测量:准确计算往返时延
- 序列号回绕保护:在高速网络中防止序列号重复使用
时间戳格式分析
TCP Option - Timestamps: TSval 1693386505, TSecr 0
- TSval(Timestamp Value):发送方的时间戳
- TSecr(Timestamp Echo Reply):对方时间戳的回显
问题根源:时间戳乱序
通过对比不同操作系统的实现发现关键差异:
Windows系统行为
连接A: TSval = base_time + random_offset_A
连接B: TSval = base_time + random_offset_B
连接C: TSval = base_time + random_offset_C
Linux默认行为(问题来源)
由于Linux内核中的安全设计,每个TCP连接都会使用不同的随机偏移:
// 源码地址:https://elixir.bootlin.com/linux/v6.1/source/net/core/secure_seq.c#L121
// Linux内核源码:net/core/secure_seq.c
u32 secure_tcp_ts_off(const struct net *net, __be32 saddr, __be32 daddr)
{
if (READ_ONCE(net->ipv4.sysctl_tcp_timestamps) != 1)
return 0;
ts_secret_init();
return siphash_3u32((__force u32)saddr,
(__force u32)daddr,
&ts_secret);
}
TCP时间戳配置模式
Linux系统提供三种时间戳模式:
| 模式 |
参数值 |
行为描述 |
安全性 |
兼容性 |
| 禁用 |
tcp_timestamps=0 |
不使用时间戳选项 |
中等 |
最佳 |
| 安全模式 |
tcp_timestamps=1 |
每连接随机偏移 |
最高 |
可能有问题 |
| 兼容模式 |
tcp_timestamps=2 |
全局单调时间戳 |
较低 |
最佳 |
优化方案
1. 系统参数调优
# 方案1:禁用时间戳(最兼容)
echo 0 > /proc/sys/net/ipv4/tcp_timestamps
# 方案2:使用兼容模式(推荐)
echo 2 > /proc/sys/net/ipv4/tcp_timestamps
# 持久化配置
echo "net.ipv4.tcp_timestamps = 2" >> /etc/sysctl.conf
sysctl -p
2. 路由器固件优化
对于网络设备厂商,建议实现更智能的时间戳检查:
// Java示例:智能时间戳验证实现
public class TCPTimestampValidator {
private static final long ACCEPTABLE_TIMESTAMP_DRIFT = 300000; // 5分钟漂移容忍度
private Map<String, ConnectionState> connections = new ConcurrentHashMap<>();
public static class ConnectionState {
private long lastSeenTimestamp;
private long connectionStartTime;
private AtomicLong packetCount = new AtomicLong(0);
public ConnectionState(long initialTimestamp) {
this.lastSeenTimestamp = initialTimestamp;
this.connectionStartTime = System.currentTimeMillis();
}
}
/**
* 验证TCP时间戳的合理性
* @param connectionKey 连接标识 (srcIP:srcPort-dstIP:dstPort)
* @param newTimestamp 新的时间戳值
* @return true如果时间戳有效,false如果应该丢弃包
*/
public boolean validateTimestamp(String connectionKey, long newTimestamp) {
ConnectionState conn = connections.get(connectionKey);
if (conn == null) {
// 新连接,记录初始时间戳
connections.put(connectionKey, new ConnectionState(newTimestamp));
return true;
}
conn.packetCount.incrementAndGet();
// 检查时间戳单调性(按连接级别,而非设备级别)
if (newTimestamp >= conn.lastSeenTimestamp) {
conn.lastSeenTimestamp = newTimestamp;
return true;
}
// 允许一定范围内的时间戳倒退(考虑时钟漂移和重排序)
long timestampDiff = conn.lastSeenTimestamp - newTimestamp;
if (timestampDiff <= ACCEPTABLE_TIMESTAMP_DRIFT) {
// 记录但不更新lastSeenTimestamp,避免时间戳倒退
logTimestampAnomaly(connectionKey, timestampDiff);
return true;
}
// 对于长连接,可能发生时间戳重置
if (isLikelyTimestampReset(conn, newTimestamp)) {
conn.lastSeenTimestamp = newTimestamp;
return true;
}
logSuspiciousTimestamp(connectionKey, conn.lastSeenTimestamp, newTimestamp);
return false;
}
private boolean isLikelyTimestampReset(ConnectionState conn, long newTimestamp) {
// 检查是否是合理的时间戳重置(比如连接迁移或系统重启)
long connectionAge = System.currentTimeMillis() - conn.connectionStartTime;
boolean longConnection = connectionAge > 3600000; // 1小时
boolean manyPackets = conn.packetCount.get() > 10000;
boolean significantReset = newTimestamp < (conn.lastSeenTimestamp / 2);
return longConnection && manyPackets && significantReset;
}
private void logTimestampAnomaly(String connectionKey, long drift) {
System.out.printf("连接 %s 时间戳小幅倒退: %d ms%n", connectionKey, drift);
}
private void logSuspiciousTimestamp(String connectionKey, long expected, long actual) {
System.out.printf("连接 %s 可疑时间戳: 期望>=%d, 实际=%d%n", connectionKey, expected, actual);
}
}
案例三:移动网络环境下的TCP重传超时问题
问题现象
移动网络环境下频繁出现:
- 页面刷新缓慢
- 应用启动时间长
- 特定功能加载失败(如快手抖音社交应用评论区卡顿)
- 切换网络时连接卡顿
TCP重传机制分析
指数退避算法
Linux内核实现的TCP重传策略:
/ 源码地址:https://elixir.bootlin.com/linux/v6.1/source/net/ipv4/tcp_timer.c#L658
// Linux内核源码:net/ipv4/tcp_timer.c
} else {
/* Use normal (exponential) backoff */
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
}
#define TCP_RTO_MIN ((unsigned)(HZ/5)) // 200ms
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) // 1s
重传时间序列
| 重传次数 |
超时时间 |
累计等待时间 |
| 初始 |
1s |
1s |
| 第1次 |
2s |
3s |
| 第2次 |
4s |
7s |
| 第3次 |
8s |
15s |
| 第4次 |
16s |
31s |
这里每次都是指数次增加时间,比如电梯里回到外面
移动网络的特殊性
1. 网络环境差异
| 特性 |
有线网络 |
移动网络 |
| 丢包原因 |
主要是拥塞 |
干扰+拥塞+切换 |
| 丢包特性 |
持续性 |
突发性、随机性 |
| 带宽变化 |
稳定 |
频繁变化 |
| 延迟 |
低且稳定 |
高且波动大 |
2. TCP设计局限性
TCP协议设计于互联网早期(1970年代),主要考虑有线网络:
- 假设前提:丢包主要由网络拥塞引起
- 重传策略:保守的指数退避,避免加剧拥塞
- 连接管理:基于四元组(源IP、源端口、目标IP、目标端口)
- 移动性支持:无原生支持,IP变化即断连
优化策略
1. 内核参数调优
# 减少初始重传超时时间
echo 200 > /proc/sys/net/ipv4/tcp_rto_min
# 启用早期重传
echo 1 > /proc/sys/net/ipv4/tcp_early_retrans
# 减少SYN重传次数
echo 2 > /proc/sys/net/ipv4/tcp_syn_retries
# 启用TCP快速恢复
echo 1 > /proc/sys/net/ipv4/tcp_frto
# 持久化配置
cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_rto_min = 200
net.ipv4.tcp_early_retrans = 1
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_frto = 1
EOF
sysctl -p
2. 应用层优化
import asyncio
import time
import logging
from typing import Optional, Dict, Any
from enum import Enum
class NetworkQuality(Enum):
EXCELLENT = 1.0
GOOD = 0.8
FAIR = 0.6
POOR = 0.4
VERY_POOR = 0.2
class AdaptiveRetryManager:
def __init__(self):
self.base_timeout = 0.5 # 500ms基础超时
self.max_retries = 5
self.network_quality = NetworkQuality.GOOD.value
self.success_count = 0
self.failure_count = 0
self.logger = logging.getLogger(__name__)
async def request_with_retry(self, url: str, **kwargs) -> Optional[Dict[str, Any]]:
"""
带自适应重试的HTTP请求
:param url: 请求URL
:param kwargs: 额外的请求参数
:return: 响应数据或None
"""
for attempt in range(self.max_retries):
try:
timeout = self.calculate_adaptive_timeout(attempt)
self.logger.info(f"尝试 {attempt + 1}/{self.max_retries}, 超时时间: {timeout:.2f}s")
start_time = time.time()
# 模拟HTTP请求(实际应用中替换为真实的HTTP客户端)
result = await self._http_request(url, timeout=timeout, **kwargs)
# 更新网络质量评分
response_time = time.time() - start_time
self._update_network_quality(response_time, success=True)
return result
except asyncio.TimeoutError:
self.logger.warning(f"请求超时: 尝试 {attempt + 1}, URL: {url}")
self._update_network_quality(0, success=False)
if attempt == self.max_retries - 1:
raise
# 移动网络使用更激进的重试策略
backoff_time = self._calculate_mobile_backoff(attempt)
await asyncio.sleep(backoff_time)
except Exception as e:
self.logger.error(f"请求失败: {e}, 尝试 {attempt + 1}")
self._update_network_quality(0, success=False)
if attempt == self.max_retries - 1:
raise
await asyncio.sleep(self._calculate_mobile_backoff(attempt))
return None
def calculate_adaptive_timeout(self, attempt: int) -> float:
"""
基于网络质量和重试次数动态调整超时时间
:param attempt: 当前重试次数
:return: 调整后的超时时间
"""
# 基础超时时间随重试次数适度增长
base = self.base_timeout * (1 + attempt * 0.3)
# 根据网络质量调整:网络质量差时给更多时间
quality_factor = 2.0 - self.network_quality
return base * quality_factor
def _calculate_mobile_backoff(self, attempt: int) -> float:
"""
为移动网络优化的退避策略
:param attempt: 重试次数
:return: 退避时间(秒)
"""
# 相比传统的指数退避,使用更温和的增长
if self.network_quality > 0.6: # 网络质量好
return min(0.1 * (attempt + 1), 1.0)
else: # 网络质量差
return min(0.2 * (attempt + 1), 2.0)
def _update_network_quality(self, response_time: float, success: bool):
"""
基于请求结果更新网络质量评分
:param response_time: 响应时间(秒)
:param success: 请求是否成功
"""
if success:
self.success_count += 1
# 根据响应时间调整质量评分
if response_time < 0.5: # 500ms以下认为优秀
improvement = 0.05
elif response_time < 1.0: # 1s以下认为良好
improvement = 0.02
elif response_time < 2.0: # 2s以下认为一般
improvement = 0.01
else: # 超过2s认为较差
improvement = -0.01
self.network_quality = min(1.0, self.network_quality + improvement)
else:
self.failure_count += 1
# 失败时降低质量评分
degradation = 0.1
self.network_quality = max(0.1, self.network_quality - degradation)
# 记录网络质量变化
total_requests = self.success_count + self.failure_count
success_rate = self.success_count / total_requests if total_requests > 0 else 0
self.logger.debug(f"网络质量: {self.network_quality:.2f}, "
f"成功率: {success_rate:.2f} ({self.success_count}/{total_requests})")
async def _http_request(self, url: str, timeout: float, **kwargs) -> Dict[str, Any]:
"""
模拟HTTP请求实现
实际应用中应替换为真实的HTTP客户端(如aiohttp)
"""
# 模拟网络请求延迟
delay = 0.1 + (1.0 - self.network_quality) * 2.0 # 网络质量差时延迟更高
try:
await asyncio.wait_for(asyncio.sleep(delay), timeout=timeout)
return {
"status": "success",
"data": f"Response from {url}",
"timestamp": time.time()
}
except asyncio.TimeoutError:
raise asyncio.TimeoutError(f"Request to {url} timed out after {timeout}s")
# 使用示例
async def main():
retry_manager = AdaptiveRetryManager()
# 模拟多个请求测试自适应能力
urls = [
"https://api.example.com/data1",
"https://api.example.com/data2",
"https://api.example.com/data3"
]
for url in urls:
try:
result = await retry_manager.request_with_retry(url)
print(f"请求成功: {url}, 结果: {result}")
except Exception as e:
print(f"请求最终失败: {url}, 错误: {e}")
# 短暂间隔
await asyncio.sleep(0.5)
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
asyncio.run(main())
3. 连接池优化
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.Map;
import java.util.List;
import java.util.ArrayList;
import java.net.Socket;
import java.net.InetSocketAddress;
/**
* 移动网络优化的智能连接池管理器
*/
public class MobileNetworkManager {
private final Map<String, ManagedConnection> connectionPool = new ConcurrentHashMap<>();
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(2);
private final ExecutorService connectionExecutor = Executors.newCachedThreadPool();
private volatile NetworkQuality currentNetworkQuality = NetworkQuality.GOOD;
public enum NetworkQuality {
EXCELLENT(1.0), GOOD(0.8), FAIR(0.6), POOR(0.4), VERY_POOR(0.2);
public final double multiplier;
NetworkQuality(double multiplier) { this.multiplier = multiplier; }
}
public static class ManagedConnection {
private final Socket socket;
private final long createdTime;
private final AtomicInteger failureCount = new AtomicInteger(0);
private volatile long lastUsedTime;
private volatile boolean healthy = true;
public ManagedConnection(Socket socket) {
this.socket = socket;
this.createdTime = System.currentTimeMillis();
this.lastUsedTime = createdTime;
}
public boolean isHealthy() {
// 检查连接健康状况
if (!healthy || socket.isClosed() || !socket.isConnected()) {
return false;
}
// 检查是否超时未使用
long idleTime = System.currentTimeMillis() - lastUsedTime;
return idleTime < 300_000; // 5分钟空闲超时
}
public void markUsed() {
this.lastUsedTime = System.currentTimeMillis();
}
public void incrementFailure() {
failureCount.incrementAndGet();
if (failureCount.get() > 3) {
healthy = false;
}
}
}
public MobileNetworkManager() {
// 启动网络质量监控
scheduler.scheduleAtFixedRate(this::monitorNetworkQuality, 0, 30, TimeUnit.SECONDS);
// 启动连接清理
scheduler.scheduleAtFixedRate(this::cleanupConnections, 60, 60, TimeUnit.SECONDS);
}
/**
* 获取到指定主机的连接
* @param host 主机地址
* @param port 端口号
* @return 可用的连接
*/
public CompletableFuture<Socket> getConnection(String host, int port) {
String key = host + ":" + port;
ManagedConnection existingConn = connectionPool.get(key);
// 检查现有连接是否健康
if (existingConn != null && existingConn.isHealthy()) {
existingConn.markUsed();
return CompletableFuture.completedFuture(existingConn.socket);
}
// 需要建立新连接
return establishBestConnection(host, port)
.thenApply(socket -> {
connectionPool.put(key, new ManagedConnection(socket));
return socket;
});
}
/**
* 并行建立多个连接,选择最快的
*/
private CompletableFuture<Socket> establishBestConnection(String host, int port) {
List<CompletableFuture<Socket>> connectionAttempts = new ArrayList<>();
// 主连接尝试
connectionAttempts.add(createConnectionAsync(host, port, 0));
// 根据网络质量决定是否启动备用连接
if (currentNetworkQuality.ordinal() >= NetworkQuality.FAIR.ordinal()) {
// 网络质量一般或较差时,启动备用连接
connectionAttempts.add(createConnectionAsync(host, port, 100)); // 100ms延迟
}
// 等待第一个成功的连接
CompletableFuture<Socket> firstSuccess = new CompletableFuture<>();
AtomicInteger completedCount = new AtomicInteger(0);
for (CompletableFuture<Socket> attempt : connectionAttempts) {
attempt.whenComplete((socket, throwable) -> {
if (throwable == null && !firstSuccess.isDone()) {
// 第一个成功的连接
firstSuccess.complete(socket);
// 取消其他连接尝试
connectionAttempts.stream()
.filter(f -> f != attempt && !f.isDone())
.forEach(f -> f.cancel(true));
} else {
// 连接失败
int completed = completedCount.incrementAndGet();
if (completed == connectionAttempts.size() && !firstSuccess.isDone()) {
firstSuccess.completeExceptionally(
new RuntimeException("All connection attempts failed"));
}
}
});
}
return firstSuccess;
}
/**
* 异步创建连接
*/
private CompletableFuture<Socket> createConnectionAsync(String host, int port, int delayMs) {
return CompletableFuture.supplyAsync(() -> {
try {
if (delayMs > 0) {
Thread.sleep(delayMs);
}
Socket socket = new Socket();
int timeout = (int) (5000 * currentNetworkQuality.multiplier);
socket.connect(new InetSocketAddress(host, port), timeout);
// 配置Socket选项
socket.setTcpNoDelay(true);
socket.setKeepAlive(true);
socket.setSoTimeout(30000); // 30秒读超时
return socket;
} catch (Exception e) {
throw new RuntimeException("Failed to connect to " + host + ":" + port, e);
}
}, connectionExecutor);
}
/**
* 监控网络质量
*/
private void monitorNetworkQuality() {
try {
// 简单的网络质量检测:ping测试
long startTime = System.currentTimeMillis();
// 这里应该实现真实的网络质量检测
// 比如ping特定服务器、测试下载速度等
CompletableFuture<Socket> testConnection = createConnectionAsync("8.8.8.8", 53, 0);
testConnection.get(5, TimeUnit.SECONDS);
long latency = System.currentTimeMillis() - startTime;
// 根据延迟评估网络质量
if (latency < 100) {
currentNetworkQuality = NetworkQuality.EXCELLENT;
} else if (latency < 300) {
currentNetworkQuality = NetworkQuality.GOOD;
} else if (latency < 800) {
currentNetworkQuality = NetworkQuality.FAIR;
} else if (latency < 2000) {
currentNetworkQuality = NetworkQuality.POOR;
} else {
currentNetworkQuality = NetworkQuality.VERY_POOR;
}
System.out.printf("网络质量评估: %s (延迟: %dms)%n",
currentNetworkQuality, latency);
} catch (Exception e) {
currentNetworkQuality = NetworkQuality.POOR;
System.err.println("网络质量检测失败: " + e.getMessage());
}
}
/**
* 清理不健康的连接
*/
private void cleanupConnections() {
connectionPool.entrySet().removeIf(entry -> {
ManagedConnection conn = entry.getValue();
if (!conn.isHealthy()) {
try {
conn.socket.close();
} catch (Exception e) {
// 忽略关闭异常
}
System.out.println("清理连接: " + entry.getKey());
return true;
}
return false;
});
System.out.printf("连接池状态: %d个活跃连接%n", connectionPool.size());
}
public void shutdown() {
scheduler.shutdown();
connectionExecutor.shutdown();
// 关闭所有连接
connectionPool.values().forEach(conn -> {
try {
conn.socket.close();
} catch (Exception e) {
// 忽略异常
}
});
connectionPool.clear();
}
}
conn = await this.establishBestConnection(host, port);
this.connections.set(key, conn);
}
return conn;
}
async establishBestConnection(host, port) {
const promises = [
this.createConnection(host, port, 'primary'),
this.createConnection(host, port, 'backup')
];
try {
// 使用最快建立的连接
return await Promise.race(promises);
} catch (error) {
// 如果并行连接都失败,尝试串行连接
return await Promise.any(promises);
}
}
}
在Android Okhttp已经实现了对应的优化逻辑
// OkHttp连接池优化配置示例
import okhttp3.*
import okhttp3.logging.HttpLoggingInterceptor
import java.util.concurrent.TimeUnit
class OptimizedOkHttpManager {
companion object {
// 单例实例,确保连接池共享
@Volatile
private var INSTANCE: OkHttpClient? = null
fun getInstance(): OkHttpClient {
return INSTANCE ?: synchronized(this) {
INSTANCE ?: buildOptimizedClient().also { INSTANCE = it }
}
}
private fun buildOptimizedClient(): OkHttpClient {
// 1. 连接池配置 - 对应原代码的connectionPool管理
val connectionPool = ConnectionPool(
maxIdleConnections = 10, // 最大空闲连接数(原代码动态管理)
keepAliveDuration = 5, // 连接保活时间
timeUnit = TimeUnit.MINUTES
)
// 2. 网络质量自适应超时配置
val builder = OkHttpClient.Builder()
.connectionPool(connectionPool)
.connectTimeout(15, TimeUnit.SECONDS) // 连接超时
.readTimeout(30, TimeUnit.SECONDS) // 读超时
.writeTimeout(30, TimeUnit.SECONDS) // 写超时
.callTimeout(60, TimeUnit.SECONDS) // 总超时
// 3. 重试机制(部分对应原代码的failureCount逻辑)
builder.retryOnConnectionFailure(true)
// 4. 添加网络质量监控拦截器
builder.addNetworkInterceptor(NetworkQualityInterceptor())
// 5. 启用HTTP/2多路复用(比原代码更高效)
builder.protocols(listOf(Protocol.HTTP_2, Protocol.HTTP_1_1))
return builder.build()
}
}
}
/**
* 网络质量监控拦截器 - 对应原代码的monitorNetworkQuality
*/
class NetworkQualityInterceptor : Interceptor {
override fun intercept(chain: Interceptor.Chain): Response {
val startTime = System.currentTimeMillis()
val request = chain.request()
try {
val response = chain.proceed(request)
val responseTime = System.currentTimeMillis() - startTime
// 记录网络质量数据
recordNetworkQuality(responseTime, true)
return response
} catch (e: Exception) {
val responseTime = System.currentTimeMillis() - startTime
recordNetworkQuality(responseTime, false)
throw e
}
}
private fun recordNetworkQuality(responseTime: Long, success: Boolean) {
// 实现网络质量评估和记录逻辑
val quality = when {
!success -> "FAILED"
responseTime < 100 -> "EXCELLENT"
responseTime < 300 -> "GOOD"
responseTime < 800 -> "FAIR"
responseTime < 2000 -> "POOR"
else -> "VERY_POOR"
}
// 可以发送到分析服务或本地存储
println("网络质量: $quality, 响应时间: ${responseTime}ms")
}
}
/**
* 使用示例 - 展示如何应用这些优化
*/
class HttpClientUsage {
private val client = OptimizedOkHttpManager.getInstance()
suspend fun makeRequest(url: String): String {
val request = Request.Builder()
.url(url)
.build()
return client.newCall(request).execute().use { response ->
if (!response.isSuccessful) {
throw Exception("Request failed: ${response.code}")
}
response.body?.string() ?: ""
}
}
// 并行请求示例(类似原代码的establishBestConnection并行逻辑)
suspend fun parallelRequests(urls: List<String>): List<String> {
return urls.map { url ->
// 每个请求都会复用连接池中的连接
makeRequest(url)
}
}
}
/**
* 高级配置 - 更细粒度的控制
*/
object AdvancedOkHttpConfig {
fun createClientWithCustomDispatcher(): OkHttpClient {
// 自定义Dispatcher控制并发
val dispatcher = Dispatcher().apply {
maxRequests = 100 // 最大并发请求数
maxRequestsPerHost = 10 // 每个主机最大并发数
}
return OkHttpClient.Builder()
.dispatcher(dispatcher)
.connectionPool(ConnectionPool(20, 5, TimeUnit.MINUTES))
// DNS解析优化(类似Happy Eyeballs)
.dns(object : Dns {
override fun lookup(hostname: String): List<java.net.InetAddress> {
// 可以实现自定义DNS解析策略
return Dns.SYSTEM.lookup(hostname)
}
})
.build()
}
}
/**
* 网络状态感知的配置(Android特有)
*/
class MobileNetworkAwareClient(private val context: Context) {
private val connectivityManager = context.getSystemService(Context.CONNECTIVITY_SERVICE) as ConnectivityManager
fun createAdaptiveClient(): OkHttpClient {
return OkHttpClient.Builder()
.addNetworkInterceptor { chain ->
val request = adaptRequestForNetworkType(chain.request())
chain.proceed(request)
}
.build()
}
private fun adaptRequestForNetworkType(request: Request): Request {
val networkInfo = connectivityManager.activeNetworkInfo
return when {
networkInfo?.type == ConnectivityManager.TYPE_WIFI -> {
// WiFi环境,可以更激进的缓存策略
request.newBuilder()
.cacheControl(CacheControl.Builder()
.maxAge(5, TimeUnit.MINUTES)
.build())
.build()
}
networkInfo?.type == ConnectivityManager.TYPE_MOBILE -> {
// 移动网络,更保守的策略
request.newBuilder()
.cacheControl(CacheControl.Builder()
.maxAge(1, TimeUnit.MINUTES)
.build())
.build()
}
else -> request
}
}
}
OkHttp的优势
- HTTP/2多路复用:一个连接可以并行处理多个请求,比TCP连接池更高效
- 自动重试和故障转移:内置重试机制
- 透明的GZIP压缩:自动处理响应压缩 A Guide to OkHttp | Baeldung
- 响应缓存:避免重复网络请求
- 更好的内存管理:经过大规模生产环境验证
建议:如果自己去优化的可以使用现成的成熟的方案借鉴。
阶段性的总结:
截止到现在我们使用了以下优化。
- 协议层分析:检查IPv6/IPv4双栈、TCP时间戳修改、重传行为
- 系统参数优化:根据网络环境调整内核参数,比如重传次数和超时时间。
- 应用层改进:实现智能重试和连接管理,与传统Okhttp等框架对齐。
但是即便如此还是解决不了TCP的对头堵塞问题,HTTP/2虽然在单个TCP连接上实现了多路复用,但底层TCP层面的队头阻塞问题依然存在,原因如下,虽然TCP链接是一个,但是在stream层面依然还是会根据数据包的序列等待,这个不是一个链接能解决的问题,而是协议层面的问题,解决方案只能替换协议。
先用图说明下这里面的原因,以及带大家从源码去看待逻辑。
HTTP/2的连接模型
HTTP/2:
Client ←→ [单个TCP连接] ←→ Server
↑
在这一个连接上复用多个stream
stream 1: GET /api/user
stream 3: POST /api/data
stream 5: GET /images/logo.png
与HTTP/1.1的对比
HTTP/1.1 (无pipeline):
Client ←→ [TCP连接1] ←→ Server (处理请求A)
Client ←→ [TCP连接2] ←→ Server (处理请求B)
Client ←→ [TCP连接3] ←→ Server (处理请求C)
HTTP/1.1 (有pipeline,但很少用):
Client ←→ [TCP连接1] ←→ Server
请求A → 请求B → 请求C
↓
响应A ← 响应B ← 响应C (必须按顺序)
HTTP/2:
Client ←→ [TCP连接1] ←→ Server
请求A、B、C同时发送
响应A、B、C可以乱序返回
这就是TCP队头阻塞的问题所在
正是因为HTTP/2只使用一个TCP连接:
TCP层面发生的情况:
[数据包1][数据包2][❌丢失][数据包4][数据包5]
↑
TCP必须等待重传数据包3
阻塞了后面所有数据包的处理
即使数据包4、5属于不同的HTTP/2 stream
再深入源码去看下,是如何检测包丢失的。既然是数据包不需要返回ack,下一个包就可以发送,那么为什么还会存在堵塞,这个包丢失的标准是什么?只能继续去看Linux源码 。
最终发现检测主要分三个,分别对应的代码也贴出来了。
// net/ipv4/tcp_input.c
/* 处理重复ACK,检测是否需要快速重传 */
static void tcp_fastretrans_alert(struct sock *sk, const u32 prior_snd_una,
int num_dupack, int *ack_flag, int *rexmit)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
int fast_rexmit = 0, flag = *ack_flag;
bool ece_ack = flag & FLAG_ECE;
/* 判断是否应该标记数据包为丢失
* 条件1: 收到重复ACK (num_dupack > 0)
* 条件2: 有SACK数据且强制快速重传条件满足
*/
bool do_lost = num_dupack || ((flag & FLAG_DATA_SACKED) &&
tcp_force_fast_retransmit(sk));
if (!tp->packets_out && tp->sacked_out)
tp->sacked_out = 0;
/* Now state machine starts.
* A. ECE, hence prohibit cwnd undoing, the reduction is required. */
if (ece_ack)
tp->prior_ssthresh = 0;
/* B. In all the states check for reneging SACKs. */
if (tcp_check_sack_reneging(sk, flag))
return;
/* C. Check consistency of the current state. */
tcp_verify_left_out(tp);
/* D. Check state exit conditions. State can be terminated
* when high_seq is ACKed. */
if (icsk->icsk_ca_state == TCP_CA_Open) {
WARN_ON(tp->retrans_out != 0 && !tp->syn_data);
tp->retrans_stamp = 0;
} else if (!before(tp->snd_una, tp->high_seq)) {
switch (icsk->icsk_ca_state) {
case TCP_CA_CWR:
/* CWR is to be held something *above* high_seq
* is ACKed for CWR bit to reach receiver. */
if (tp->snd_una != tp->high_seq) {
tcp_end_cwnd_reduction(sk);
tcp_set_ca_state(sk, TCP_CA_Open);
}
break;
case TCP_CA_Recovery:
if (tcp_is_reno(tp))
tcp_reset_reno_sack(tp);
if (tcp_try_undo_recovery(sk))
return;
tcp_end_cwnd_reduction(sk);
break;
}
}
------
if (!tcp_is_rack(sk) && do_lost)
tcp_update_scoreboard(sk, fast_rexmit);
*rexmit = REXMIT_LOST;
}
发送方为每个未确认的数据包设置定时器:
/* Called to compute a smoothed rtt estimate. The data fed to this
* routine either comes from timestamps, or from segments that were
* known _not_ to have been retransmitted [see Karn/Partridge
* Proceedings SIGCOMM 87]. The algorithm is from the SIGCOMM 88
* piece by Van Jacobson.
* NOTE: the next three routines used to be one big routine.
* To save cycles in the RFC 1323 implementation it was better to break
* it up into three procedures. -- erics
*/
static void tcp_rtt_estimator(struct sock *sk, long mrtt_us)
{
struct tcp_sock *tp = tcp_sk(sk);
long m = mrtt_us; /* RTT */
u32 srtt = tp->srtt_us; // 测量的RTT
/* The following amusing code comes from Jacobson's
* article in SIGCOMM '88. Note that rtt and mdev
* are scaled versions of rtt and mean deviation.
* This is designed to be as fast as possible
* m stands for "measurement".
*
* On a 1990 paper the rto value is changed to:
* RTO = rtt + 4 * mdev
*
* Funny. This algorithm seems to be very broken.
* These formulae increase RTO, when it should be decreased, increase
* too slowly, when it should be increased quickly, decrease too quickly
* etc. I guess in BSD RTO takes ONE value, so that it is absolutely
* does not matter how to _calculate_ it. Seems, it was trap
* that VJ failed to avoid. 8)
*/
/* 首次RTT测量 */
if (srtt != 0) {
/* 更新平滑RTT:SRTT = 7/8 * SRTT + 1/8 * R' */
m -= (srtt >> 3); /* m is now error in rtt est */
srtt += m; /* rtt = 7/8 rtt + 1/8 new */
if (m < 0) {
m = -m; /* m is now abs(error) */
m -= (tp->mdev_us >> 2); /* similar update on mdev */
/* This is similar to one of Eifel findings.
* Eifel blocks mdev updates when rtt decreases.
* This solution is a bit different: we use finer gain
* for mdev in this case (alpha*beta).
* Like Eifel it also prevents growth of rto,
* but also it limits too fast rto decreases,
* happening in pure Eifel.
*/
if (m > 0)
m >>= 3;
} else {
/* 第一次RTT测量:SRTT = R', RTTVAR = R'/2 */
m -= (tp->mdev_us >> 2); /* similar update on mdev */
}
tp->mdev_us += m; /* mdev = 3/4 mdev + 1/4 new */
if (tp->mdev_us > tp->mdev_max_us) {
tp->mdev_max_us = tp->mdev_us;
if (tp->mdev_max_us > tp->rttvar_us)
tp->rttvar_us = tp->mdev_max_us;
}
if (after(tp->snd_una, tp->rtt_seq)) {
if (tp->mdev_max_us < tp->rttvar_us)
tp->rttvar_us -= (tp->rttvar_us - tp->mdev_max_us) >> 2;
tp->rtt_seq = tp->snd_nxt;
tp->mdev_max_us = tcp_rto_min_us(sk);
tcp_bpf_rtt(sk);
}
} else {
/* no previous measure. */
srtt = m << 3; /* take the measured time to be rtt */
tp->mdev_us = m << 1; /* make sure rto = 3*rtt */
tp->rttvar_us = max(tp->mdev_us, tcp_rto_min_us(sk));
tp->mdev_max_us = tp->rttvar_us;
tp->rtt_seq = tp->snd_nxt;
tcp_bpf_rtt(sk);
}
tp->srtt_us = max(1U, srtt);
}
重传定时器处理
void tcp_retransmit_timer(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock *req;
struct sk_buff *skb;
req = rcu_dereference_protected(tp->fastopen_rsk,
lockdep_sock_is_held(sk));
if (req) {
WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV &&
sk->sk_state != TCP_FIN_WAIT1);
tcp_fastopen_synack_timer(sk, req);
/* Before we receive ACK to our SYN-ACK don't retransmit
* anything else (e.g., data or FIN segments).
*/
return;
}
if (!tp->packets_out)
return;
skb = tcp_rtx_queue_head(sk);
if (WARN_ON_ONCE(!skb))
return;
if (!tp->snd_wnd && !sock_flag(sk, SOCK_DEAD) &&
!((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV))) {
/* Receiver dastardly shrinks window. Our retransmits
* become zero probes, but we should not timeout this
* connection. If the socket is an orphan, time it out,
* we cannot allow such beasts to hang infinitely.
*/
struct inet_sock *inet = inet_sk(sk);
u32 rtx_delta;
rtx_delta = tcp_time_stamp_ts(tp) - (tp->retrans_stamp ?:
tcp_skb_timestamp_ts(tp->tcp_usec_ts, skb));
if (tp->tcp_usec_ts)
rtx_delta /= USEC_PER_MSEC;
if (sk->sk_family == AF_INET) {
net_dbg_ratelimited("Probing zero-window on %pI4:%u/%u, seq=%u:%u, recv %ums ago, lasting %ums\n",
&inet->inet_daddr, ntohs(inet->inet_dport),
inet->inet_num, tp->snd_una, tp->snd_nxt,
jiffies_to_msecs(jiffies - tp->rcv_tstamp),
rtx_delta);
}
#if IS_ENABLED(CONFIG_IPV6)
else if (sk->sk_family == AF_INET6) {
net_dbg_ratelimited("Probing zero-window on %pI6:%u/%u, seq=%u:%u, recv %ums ago, lasting %ums\n",
&sk->sk_v6_daddr, ntohs(inet->inet_dport),
inet->inet_num, tp->snd_una, tp->snd_nxt,
jiffies_to_msecs(jiffies - tp->rcv_tstamp),
rtx_delta);
}
#endif
if (tcp_rtx_probe0_timed_out(sk, skb, rtx_delta)) {
tcp_write_err(sk);
goto out;
}
tcp_enter_loss(sk);
tcp_retransmit_skb(sk, skb, 1);
__sk_dst_reset(sk);
goto out_reset_timer;
}
__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPTIMEOUTS);
if (tcp_write_timeout(sk))
goto out;
if (icsk->icsk_retransmits == 0) {
int mib_idx = 0;
if (icsk->icsk_ca_state == TCP_CA_Recovery) {
if (tcp_is_sack(tp))
mib_idx = LINUX_MIB_TCPSACKRECOVERYFAIL;
else
mib_idx = LINUX_MIB_TCPRENORECOVERYFAIL;
} else if (icsk->icsk_ca_state == TCP_CA_Loss) {
mib_idx = LINUX_MIB_TCPLOSSFAILURES;
} else if ((icsk->icsk_ca_state == TCP_CA_Disorder) ||
tp->sacked_out) {
if (tcp_is_sack(tp))
mib_idx = LINUX_MIB_TCPSACKFAILURES;
else
mib_idx = LINUX_MIB_TCPRENOFAILURES;
}
if (mib_idx)
__NET_INC_STATS(sock_net(sk), mib_idx);
}
tcp_enter_loss(sk);
tcp_update_rto_stats(sk);
if (tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1) > 0) {
/* Retransmission failed because of local congestion,
* Let senders fight for local resources conservatively.
*/
tcp_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
TCP_RESOURCE_PROBE_INTERVAL,
false);
goto out;
}
out_reset_timer:
if (sk->sk_state == TCP_ESTABLISHED &&
(tp->thin_lto || READ_ONCE(net->ipv4.sysctl_tcp_thin_linear_timeouts)) &&
tcp_stream_is_thin(tp) &&
icsk->icsk_retransmits <= TCP_THIN_LINEAR_RETRIES) {
icsk->icsk_backoff = 0;
icsk->icsk_rto = clamp(__tcp_set_rto(tp),
tcp_rto_min(sk),
tcp_rto_max(sk));
} else if (sk->sk_state != TCP_SYN_SENT ||
tp->total_rto >
READ_ONCE(net->ipv4.sysctl_tcp_syn_linear_timeouts)) {
/* Use normal (exponential) backoff unless linear timeouts are
* activated.
*/
icsk->icsk_backoff++;
icsk->icsk_rto = min(icsk->icsk_rto << 1, tcp_rto_max(sk));
}
tcp_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
tcp_clamp_rto_to_user_timeout(sk), false);
if (retransmits_timed_out(sk, READ_ONCE(net->ipv4.sysctl_tcp_retries1) + 1, 0))
__sk_dst_reset(sk);
out:;
}
现代TCP实现中,接收方可以告诉发送方具体哪些包收到了:如果没有收到的话,重新上传,原因是TCP的一种机制,用于在发生丢包时,接收方可以通知发送方哪些数据段已经成功接收,即使这些数据段不是连续的。这样,发送方可以只重传丢失的数据段,而不是重传整个窗口的数据,提高了效率。代码:https://elixir.bootlin.com/linux/v6.15.7/source/net/ipv4/tcp_timer.c#L520
SACK选项: 收到300-400, 500-600 → 发送方知道200和400-500之间的包丢了
// net/ipv4/tcp_input.c
/* 处理SACK信息,更精确地检测丢包 */
static int tcp_sack_cache_ok(const struct tcp_sock *tp, const struct sk_buff *skb)
{
/* 检查SACK缓存是否有效 */
return cache != NULL &&
!after(start_seq, cache->end_seq) &&
!before(end_seq, cache->start_seq);
}
tatic int
tcp_sacktag_write_queue(struct sock *sk, const struct sk_buff *ack_skb,
u32 prior_snd_una, struct tcp_sacktag_state *state)
{
struct tcp_sock *tp = tcp_sk(sk);
const unsigned char *ptr = (skb_transport_header(ack_skb) +
TCP_SKB_CB(ack_skb)->sacked);
struct tcp_sack_block_wire *sp_wire = (struct tcp_sack_block_wire *)(ptr + 2);
struct tcp_sack_block sp[TCP_NUM_SACKS];
int num_sacks = min(TCP_NUM_SACKS, (ptr[1] - TCPOLEN_SACK_BASE) >> 3);
/* 解析SACK块信息 */
for (i = 0; i < num_sacks; i++) {
sp[i].start_seq = get_unaligned_be32(&sp_wire[i].start_seq);
sp[i].end_seq = get_unaligned_be32(&sp_wire[i].end_seq);
}
/* 基于SACK信息标记确认和丢失的数据包 */
for (i = 0; i < num_sacks; i++) {
tcp_sacktag_one(sk, state, sp[i].start_seq, sp[i].end_seq,
TCP_SKB_CB(ack_skb)->acked, pcount,
&fack_count);
}
/* 根据SACK信息进行丢失检测 */
tcp_mark_lost_retrans(sk);
tcp_verify_left_out(tp);
}
好了,上面分析了TCP从源码层面去分析遇到的问题和挑战,以及我们使用哪些手段可以优化,但是还是没有回答一个问题,TCP的数据包堵塞 问题到底能不能根治?
根本解决方案:QUIC/Http3协议
虽然TCP层面的优化能在一定程度上改善用户体验,但要从根本上解决移动网络的连接问题,需要采用新一代的传输协议。
QUIC协议核心优势
1. 连接迁移支持
传统TCP连接标识: (源IP, 源端口, 目标IP, 目标端口)
QUIC连接标识: Connection ID (64位唯一标识符)
优势:当设备在WiFi和移动网络间切换时,QUIC连接可以无缝迁移,而TCP连接必须重新建立。
2. 0-RTT/1-RTT握手
TCP握手(1.5-RTT): 客户端 -> SYN -> 服务器 客户端 <- SYN/ACK <- 服务器
客户端 -> ACK -> 服务器 [然后才能发送数据]
QUIC握手(1-RTT): 客户端 -> Initial + 0-RTT数据 -> 服务器 客户端 <- Handshake + 数据 <- 服务器 [数据传输已开始]
3. 多路复用无队头阻塞
# 概念示例
class QUICConnection:
def __init__(self):
self.streams = {} # 多个独立流
def handle_packet_loss(self, lost_stream_id):
# 只影响特定流,其他流继续传输
stream = self.streams[lost_stream_id]
stream.request_retransmission()
# 其他流不受影响
for stream_id, stream in self.streams.items():
if stream_id != lost_stream_id:
stream.continue_transmission()l
流程
单个UDP连接 + QUIC层多路复用:
Client ←→ [ 单个UDP连接 ] ←→ Server
│ QUIC Stream 1 (独立可靠传输) │
│ QUIC Stream 3 (独立可靠传输) │
│ QUIC Stream 5 (独立可靠传输) │
└─────────────────────────────┘
↓
QUIC层处理:
Stream 1: [包1][包2][包3][包4] ✓ 完整接收
Stream 3: [包1][❌丢失][包3] → 只重传Stream3的包2,不影响其他stream
Stream 5: [包1][包2] ✓ 完整接收
UDP层面:
[UDP包1][UDP包2][❌丢失][UDP包4][UDP包5]
↓ ↓ ↓ ↓
Stream1 Stream3 Stream5 Stream1
正常处理 重传包2 正常处理 正常处理
行业采用情况
目前国内主流的微信、抖音都已经采用Quic协议
案例4:双带WIFI+蜂窝三网并发,打游戏依然卡顿
技术分析:
- 游戏类应用大多采用UDP协议,数据传输基于单个报文而不是连接,实际上是可以做多网并发的
- 但由于应用厂商和终端厂商缺少合作,应用端不了解系统的能力,终端的能力实际上完全没有发挥出来
怎么理解第一句话:UDP的优势 – 每个数据包独立,可以选择蜂窝,5G或者其他建立路径,可以灵活选择发送路径。
// TCP的限制 - 连接绑定到特定路径
class TCPConnection {
private:
int socket_fd; // 绑定到特定的网络接口
struct sockaddr_in local_addr; // 本地地址
struct sockaddr_in remote_addr; // 远程地址
ConnectionState state; // 连接状态
public:
bool Connect(const std::string& server_ip, uint16_t port) {
// TCP连接一旦建立,就绑定到特定的网络路径
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
// 连接建立后,所有数据都必须通过这个socket发送
if (connect(socket_fd, (sockaddr*)&remote_addr, sizeof(remote_addr)) == 0) {
state = CONNECTED;
return true;
}
return false;
}
// 问题:无法中途切换网络路径
bool SendData(const char* data, size_t len) {
// 所有数据都通过同一个socket发送
return send(socket_fd, data, len, 0) == len;
}
};
// UDP的优势 - 每个数据包独立
class UDPMultiPath {
private:
struct NetworkPath {
int socket_fd;
std::string interface_name;
struct sockaddr_in local_addr;
bool is_active;
};
std::vector<NetworkPath> network_paths_;
public:
bool InitializeMultiplePaths() {
// 可以创建多个UDP socket,绑定到不同网络接口
// WiFi网络路径
NetworkPath wifi_path;
wifi_path.socket_fd = socket(AF_INET, SOCK_DGRAM, 0);
wifi_path.interface_name = "wlan0";
// 绑定到WiFi接口
if (setsockopt(wifi_path.socket_fd, SOL_SOCKET, SO_BINDTODEVICE,
"wlan0", 5) == 0) {
network_paths_.push_back(wifi_path);
}
// 5G网络路径
NetworkPath cellular_path;
cellular_path.socket_fd = socket(AF_INET, SOCK_DGRAM, 0);
cellular_path.interface_name = "rmnet0";
// 绑定到蜂窝接口
if (setsockopt(cellular_path.socket_fd, SOL_SOCKET, SO_BINDTODEVICE,
"rmnet0", 6) == 0) {
network_paths_.push_back(cellular_path);
}
return !network_paths_.empty();
}
// UDP的优势:可以灵活选择发送路径
bool SendGamePacket(const GamePacket& packet, const sockaddr_in& dest_addr) {
// 根据数据包类型和网络状况选择最优路径
NetworkPath* selected_path = SelectOptimalPath(packet.type, packet.size);
if (selected_path && selected_path->is_active) {
// 每个UDP数据包可以独立选择网络路径
ssize_t sent = sendto(selected_path->socket_fd,
&packet, sizeof(packet), 0,
(sockaddr*)&dest_addr, sizeof(dest_addr));
return sent == sizeof(packet);
}
return false;
}
// 甚至可以同时在多个路径上发送同一个数据包(冗余发送)
bool SendCriticalPacket(const GamePacket& packet, const sockaddr_in& dest_addr) {
bool success = false;
// 在所有可用路径上都发送这个关键数据包
for (auto& path : network_paths_) {
if (path.is_active) {
ssize_t sent = sendto(path.socket_fd,
&packet, sizeof(packet), 0,
(sockaddr*)&dest_addr, sizeof(dest_addr));
if (sent == sizeof(packet)) {
success = true;
}
}
}
return success;
}
};
怎么理解第二句话:/应用完全不知道这个数据包会从哪个网络接口发出 ,可能是WiFi,可能是5G,完全由系统决定 , 如果WiFi质量很差,但系统默认选择WiFi,游戏就会卡,系统告诉应用:当前网络质量评分,根据当前的情况动态的选择,因为应用可以根据自己的业务场景决定如果当前网络情况,保证流畅度更重要,暂停其他的下载等等网络服务。
优化思路:
- 应用+终端优化:应用自己在应用层和服务器端实现连接迁移,同时和终端厂商合作做多网并发策略
- 第三方应用+终端优化:发挥第三方优势,操作系统和应用协同,实现无感并发(有落地内核双发双路通信)
- 终端官方加速器:直接搭服务器搞手机官方VPN,本机的多网多个IP地址映射到中转服务器的同一个对外端口和地址,由中转服务器进行NAT,中转服务器访问远端就还是自由一个IP,本机三网可以随便切,算是解决了问题。但是中转服务器位置不合适的话可能有负优化。
方案一:应用+终端优化
1.1 核心思路
应用感知多网络能力,与终端SDK深度合作,在应用层实现智能连接管理和服务器端状态同步。
方案二:第三方应用+终端优化(无感并发)
2.1 核心思路
操作系统透明地为应用提供多网络能力,应用无需修改代码,系统内核级别实现双发双路。
方案三:终端官方加速器
3.1 核心思路
手机厂商部署加速服务器,通过VPN隧道将多网络流量聚合到中转服务器,由中转服务器统一对外通信,实现网络加速和无缝切换。核心是解决ip切换的问题。比如王者荣耀会跟三方应用合作,https://pvp.qq.com/webplat/info/news_version3/15592/24091/24092/24095/m15241/201609/503487.shtml
// 官方VPN客户端 - 多隧道管理器
class OfficialVPNClient {
private:
struct VPNTunnel {
uint32_t tunnel_id;
std::string interface_name; // "wlan0", "rmnet0", "starlink0"
NetworkType network_type; // WiFi, Cellular_5G, Starlink
std::string local_ip;
std::string tunnel_server_ip;
uint16_t tunnel_server_port;
// 隧道状态
TunnelState state;
std::unique_ptr<WireGuardTunnel> wireguard;
std::chrono::steady_clock::time_point last_heartbeat;
// 质量指标
TunnelQuality quality;
uint64_t bytes_sent;
uint64_t bytes_received;
uint32_t connection_failures;
};
struct EdgeServerInfo {
std::string server_id;
std::string server_ip;
std::string location; // "Beijing", "Shanghai", "Shenzhen"
uint32_t estimated_rtt_ms;
float server_load; // 0.0 - 1.0
bool is_available;
uint32_t user_count;
};
std::vector<VPNTunnel> tunnels_;
std::vector<EdgeServerInfo> edge_servers_;
std::unique_ptr<TunnelLoadBalancer> load_balancer_;
std::unique_ptr<AutoSwitchManager> auto_switch_;
std::thread tunnel_monitor_;
std::atomic<bool> running_;
public:
// 初始化多隧道VPN
bool Initialize() {
running_ = true;
// 1. 从云端获取最优边缘服务器列表
if (!RefreshEdgeServerList()) {
LOG_ERROR("Failed to get edge server list");
return false;
}
// 2. 为每个网络接口建立隧道
auto network_interfaces = GetAvailableNetworkInterfaces();
for (const auto& interface : network_interfaces) {
if (CreateTunnelForInterface(interface)) {
LOG_INFO("Created tunnel for interface: %s", interface.name.c_str());
}
}
if (tunnels_.empty()) {
LOG_ERROR("No tunnels created");
return false;
}
// 3. 初始化负载均衡器
load_balancer_ = std::make_unique<TunnelLoadBalancer>(tunnels_);
// 4. 初始化自动切换管理器
auto_switch_ = std::make_unique<AutoSwitchManager>(tunnels_, edge_servers_);
// 5. 启动隧道监控
tunnel_monitor_ = std::thread(&OfficialVPNClient::MonitorTunnels, this);
LOG_INFO("Official VPN client initialized with %zu tunnels", tunnels_.size());
return true;
}
// 为特定网络接口创建隧道
bool CreateTunnelForInterface(const NetworkInterface& interface) {
// 选择最优边缘服务器
EdgeServerInfo* best_server = SelectOptimalEdgeServer(interface);
if (!best_server) {
LOG_ERROR("No suitable edge server for interface %s", interface.name.c_str());
return false;
}
VPNTunnel tunnel;
tunnel.tunnel_id = GenerateTunnelId();
tunnel.interface_name = interface.name;
tunnel.network_type = interface.type;
tunnel.local_ip = interface.ip_address;
tunnel.tunnel_server_ip = best_server->server_ip;
tunnel.tunnel_server_port = 51820; // WireGuard default port
tunnel.state = TunnelState::DISCONNECTED;
// 创建WireGuard隧道
WireGuardConfig wg_config;
wg_config.private_key = GeneratePrivateKey();
wg_config.server_public_key = GetServerPublicKey(best_server->server_id);
wg_config.server_endpoint = best_server->server_ip + ":51820";
wg_config.allowed_ips = "0.0.0.0/0"; // 全流量
wg_config.bind_interface = interface.name; // 绑定到特定接口
tunnel.wireguard = std::make_unique<WireGuardTunnel>(wg_config);
// 建立隧道连接
if (tunnel.wireguard->Connect()) {
tunnel.state = TunnelState::CONNECTED;
tunnel.last_heartbeat = std::chrono::steady_clock::now();
tunnels_.push_back(std::move(tunnel));
LOG_INFO("Tunnel created: interface=%s, server=%s, tunnel_id=%u",
interface.name.c_str(), best_server->server_ip.c_str(), tunnel.tunnel_id);
return true;
} else {
LOG_ERROR("Failed to connect tunnel for interface %s", interface.name.c_str());
return false;
}
}
// 智能边缘服务器选择
EdgeServerInfo* SelectOptimalEdgeServer(const NetworkInterface& interface) {
struct ServerScore {
EdgeServerInfo* server;
float total_score;
float latency_score;
float load_score;
float distance_score;
};
std::vector<ServerScore> scored_servers;
for (auto& server : edge_servers_) {
if (!server.is_available) continue;
ServerScore score;
score.server = &server;
// 延迟评分 (40%权重)
float latency_penalty = std::min(server.estimated_rtt_ms / 100.0f, 1.0f);
score.latency_score = (1.0f - latency_penalty) * 40.0f;
// 服务器负载评分 (30%权重)
score.load_score = (1.0f - server.server_load) * 30.0f;
// 地理距离评分 (20%权重) - 基于用户位置
float distance_score = CalculateGeographicScore(server.location, GetUserLocation());
score.distance_score = distance_score * 20.0f;
// 网络类型匹配度 (10%权重)
float network_match_score = CalculateNetworkMatchScore(interface.type, server);
score.total_score = score.latency_score + score.load_score +
score.distance_score + network_match_score;
scored_servers.push_back(score);
}
if (scored_servers.empty()) return nullptr;
// 按总分排序
std::sort(scored_servers.begin(), scored_servers.end(),
[](const ServerScore& a, const ServerScore& b) {
return a.total_score > b.total_score;
});
LOG_INFO("Selected edge server: %s (score: %.2f, latency: %ums, load: %.2f)",
scored_servers[0].server->server_id.c_str(),
scored_servers[0].total_score,
scored_servers[0].server->estimated_rtt_ms,
scored_servers[0].server->server_load);
return scored_servers[0].server;
}
// 隧道质量监控和自动切换
void MonitorTunnels() {
while (running_) {
auto now = std::chrono::steady_clock::now();
for (auto& tunnel : tunnels_) {
if (tunnel.state != TunnelState::CONNECTED) continue;
// 测量隧道质量
TunnelQuality quality = MeasureTunnelQuality(tunnel);
tunnel.quality = quality;
// 检查隧道健康状况
auto time_since_heartbeat = now - tunnel.last_heartbeat;
if (time_since_heartbeat > std::chrono::seconds(30)) {
LOG_WARNING("Tunnel %u heartbeat timeout", tunnel.tunnel_id);
// 尝试重连
if (!tunnel.wireguard->Reconnect()) {
tunnel.state = TunnelState::FAILED;
tunnel.connection_failures++;
// 如果失败次数过多,切换到其他边缘服务器
if (tunnel.connection_failures >= 3) {
SwitchTunnelToNewServer(tunnel);
}
}
}
// 发送心跳
SendTunnelHeartbeat(tunnel);
}
// 检查是否需要自动切换
auto_switch_->CheckAndExecuteSwitch();
std::this_thread::sleep_for(std::chrono::seconds(5));
}
}
private:
// 隧道质量测量
TunnelQuality MeasureTunnelQuality(const VPNTunnel& tunnel) {
TunnelQuality quality;
// 1. RTT测量 - 通过隧道ping服务器
auto ping_start = std::chrono::high_resolution_clock::now();
bool ping_success = tunnel.wireguard->SendPing();
if (ping_success) {
auto ping_end = std::chrono::high_resolution_clock::now();
quality.rtt_ms = std::chrono::duration_cast<std::chrono::milliseconds>(
ping_end - ping_start).count();
} else {
quality.rtt_ms = 9999; // 超时
}
// 2. 带宽测量 - 发送测试数据
quality.bandwidth_mbps = MeasureTunnelBandwidth(tunnel);
// 3. 丢包率 - 基于统计数据
quality.packet_loss_rate = CalculatePacketLossRate(tunnel);
// 4. 综合评分
quality.overall_score = CalculateOverallScore(quality);
return quality;
}
// 自动切换到新的边缘服务器
bool SwitchTunnelToNewServer(VPNTunnel& tunnel) {
LOG_INFO("Switching tunnel %u to new server", tunnel.tunnel_id);
// 获取网络接口信息
NetworkInterface interface = GetNetworkInterface(tunnel.interface_name);
// 排除当前失败的服务器,选择新的服务器
std::string current_server_ip = tunnel.tunnel_server_ip;
EdgeServerInfo* new_server = nullptr;
for (auto& server : edge_servers_) {
if (server.server_ip != current_server_ip && server.is_available) {
// 简单选择第一个可用的不同服务器
new_server = &server;
break;
}
}
if (!new_server) {
LOG_ERROR("No alternative server available for tunnel %u", tunnel.tunnel_id);
return false;
}
// 断开当前隧道
tunnel.wireguard->Disconnect();
// 重新配置隧道到新服务器
WireGuardConfig new_config;
new_config.private_key = tunnel.wireguard->GetPrivateKey();
new_config.server_public_key = GetServerPublicKey(new_server->server_id);
new_config.server_endpoint = new_server->server_ip + ":51820";
new_config.allowed_ips = "0.0.0.0/0";
new_config.bind_interface = tunnel.interface_name;
tunnel.wireguard->UpdateConfig(new_config);
// 连接到新服务器
if (tunnel.wireguard->Connect()) {
tunnel.tunnel_server_ip = new_server->server_ip;
tunnel.state = TunnelState::CONNECTED;
tunnel.connection_failures = 0;
tunnel.last_heartbeat = std::chrono::steady_clock::now();
LOG_INFO("Successfully switched tunnel %u to server %s",
tunnel.tunnel_id, new_server->server_ip.c_str());
return true;
} else {
LOG_ERROR("Failed to connect to new server %s", new_server->server_ip.c_str());
tunnel.state = TunnelState::FAILED;
return false;
}
}
};
// 自动切换管理器
class AutoSwitchManager {
private:
std::vector<VPNTunnel>& tunnels_;
std::vector<EdgeServerInfo>& edge_servers_;
struct SwitchThresholds {
uint32_t max_rtt_ms = 200; // 最大可接受RTT
float max_packet_loss = 0.05f; // 最大可接受丢包率
float min_bandwidth_mbps = 1.0f; // 最小可接受带宽
uint32_t quality_check_window = 30; // 质量检查窗口(秒)
} thresholds_;
public:
AutoSwitchManager(std::vector<VPNTunnel>& tunnels,
std::vector<EdgeServerInfo>& servers)
: tunnels_(tunnels), edge_servers_(servers) {}
// 检查并执行自动切换
void CheckAndExecuteSwitch() {
// 1. 检查当前活跃隧道质量
for (auto& tunnel : tunnels_) {
if (tunnel.state != TunnelState::CONNECTED) continue;
if (ShouldSwitchTunnel(tunnel)) {
ExecuteTunnelSwitch(tunnel);
}
}
// 2. 检查是否需要启用新的隧道
CheckForNewTunnelOpportunities();
// 3. 检查是否需要禁用质量差的隧道
CheckForTunnelDisabling();
}
private:
bool ShouldSwitchTunnel(const VPNTunnel& tunnel) {
const TunnelQuality& quality = tunnel.quality;
// RTT过高
if (quality.rtt_ms > thresholds_.max_rtt_ms) {
LOG_DEBUG("Tunnel %u RTT too high: %ums", tunnel.tunnel_id, quality.rtt_ms);
return true;
}
// 丢包率过高
if (quality.packet_loss_rate > thresholds_.max_packet_loss) {
LOG_DEBUG("Tunnel %u packet loss too high: %.3f",
tunnel.tunnel_id, quality.packet_loss_rate);
return true;
}
// 带宽过低
if (quality.bandwidth_mbps < thresholds_.min_bandwidth_mbps) {
LOG_DEBUG("Tunnel %u bandwidth too low: %.2f Mbps",
tunnel.tunnel_id, quality.bandwidth_mbps);
return true;
}
return false;
}
void ExecuteTunnelSwitch(VPNTunnel& tunnel) {
// 寻找更好的边缘服务器
EdgeServerInfo* better_server = FindBetterServer(tunnel);
if (!better_server) {
LOG_DEBUG("No better server found for tunnel %u", tunnel.tunnel_id);
return;
}
LOG_INFO("Auto-switching tunnel %u from %s to %s",
tunnel.tunnel_id, tunnel.tunnel_server_ip.c_str(),
better_server->server_ip.c_str());
// 执行服务器切换
SwitchTunnelToServer(tunnel, *better_server);
}
EdgeServerInfo* FindBetterServer(const VPNTunnel& tunnel) {
EdgeServerInfo* best_alternative = nullptr;
float best_score = tunnel.quality.overall_score;
for (auto& server : edge_servers_) {
if (server.server_ip == tunnel.tunnel_server_ip) continue;
if (!server.is_available) continue;
// 估算切换到此服务器的质量提升
float estimated_score = EstimateServerScore(server, tunnel);
// 需要显著提升才值得切换 (避免频繁切换)
if (estimated_score > best_score + 10.0f) {
best_score = estimated_score;
best_alternative = &server;
}
}
return best_alternative;
}
};
案例5:Wifi与蓝牙公用频率波段
四种通信资源的冲突
1. 硬件冲突
- 频段重合:WiFi物理层和BT物理层都使用2.4GHz频段
- 成本考虑:为节省成本,一些芯片的WiFi和BT会复用射频器件
- 混频器冲突:当蓝牙使用该混频器时,WiFi就无法使用,需要选择开关进行控制
2. 频谱冲突
2.4GHz频段拥挤:
- WiFi 2.4G与BT共通路:两者都工作在2.4GHz,无法并发
- 5G独立通路:WiFi可以使用5GHz频段,与BT互不干扰
- 最糟情况:WiFi 2.4G/5G/BT共通路时,三者完全无法并发
3. 空间冲突
- 天线共享或天线间相互干扰
- 射频前端电路的物理隔离不足
4. 时间冲突
- 两个协议都需要占用时间资源
- 传输时机冲突导致数据包碰撞
解决方案
华为星闪方案:从根本上重新设计统一的短距离通信标准,SLB模式:主要工作在5GHz频段,避开2.4GHz拥挤频段,彻底解决共存问题
时分调度:当无法并发时,只能依赖时分调度
- WiFi和BT轮流使用共享资源
- 通过智能调度算法最小化性能影响
- 根据业务优先级动态分配时间片
长期技术趋势
- 协议演进:HTTP/3和QUIC将逐渐成为主流
- 网络智能化:AI驱动的网络优化将更加普及,比如应用内部,系统内部根据用户场景和网络情况,动态智能化做网络切换。
- 类似于星闪的技术:重新定义WIFI的协议栈,当然对于技术要求更高,对于自己业务场景,无需感知wifi还是蜂窝或者蓝牙。
通过系统性地理解和优化网络协议栈的各个层面,我们可以显著改善用户的网络体验,特别是在移动网络环境下。随着QUIC等新协议的成熟和普及,这些底层的网络问题将得到更根本的解决。局部最优不一定是全局最优,安全与性能做一个平衡,是我们工程师不得不做的事情。

 沪ICP备2025124802号-1
沪ICP备2025124802号-1