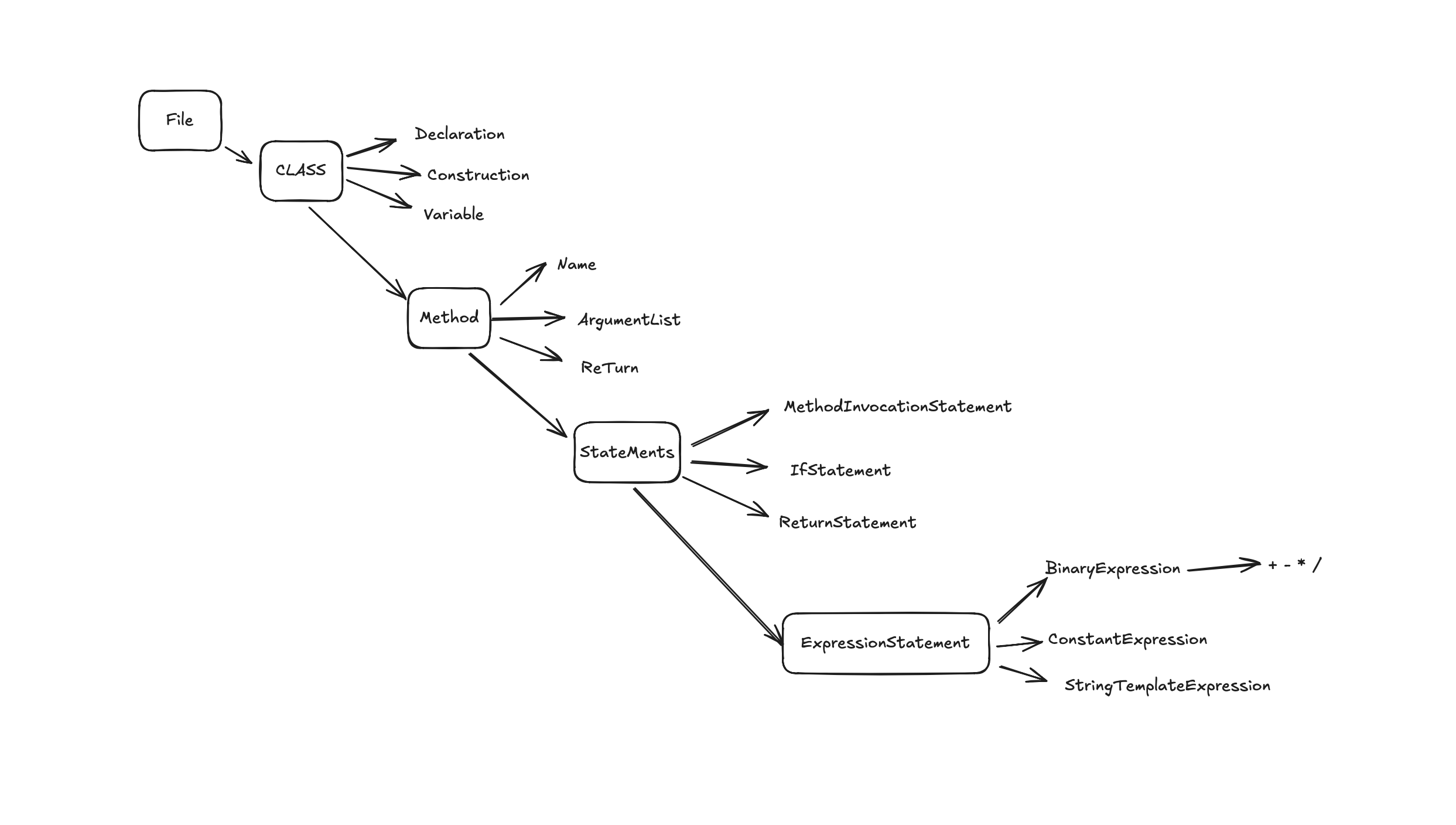
// Modules/gcmodule.c 详细展开
static Py_ssize_t
gc_collect_main(PyThreadState *tstate, int generation,
Py_ssize_t *n_collected, Py_ssize_t *n_uncollectable,
int nofail)
{
int i;
Py_ssize_t m = 0; /* # objects collected */
Py_ssize_t n = 0; /* # unreachable objects that couldn't be collected */
PyGC_Head *young; /* the generation we are examining */
PyGC_Head *old; /* next older generation */
PyGC_Head unreachable; /* non-problematic unreachable trash */
PyGC_Head finalizers; /* objects with, & reachable from, __del__ */
PyGC_Head *gc;
_PyTime_t t1 = 0; /* initialize to prevent a compiler warning */
GCState *gcstate = &tstate->interp->gc;
// gc_collect_main() must not be called before _PyGC_Init
// or after _PyGC_Fini()
assert(gcstate->garbage != NULL);
assert(!_PyErr_Occurred(tstate));
if (gcstate->debug & DEBUG_STATS) {
PySys_WriteStderr("gc: collecting generation %d...\n", generation);
show_stats_each_generations(gcstate);
t1 = _PyTime_GetPerfCounter();
}
if (PyDTrace_GC_START_ENABLED())
PyDTrace_GC_START(generation);
**//重置当前代及更年轻代的计数器,增加下一代的计数器,之所以重制当前代的计数器,是为了完成垃圾回收后,当前的计数器还处于较高的峰值,再次触发回收,给下一代增加1 ,这个很好理解,为了出发老年代的对象**
/* update collection and allocation counters */
if (generation+1 < NUM_GENERATIONS)
gcstate->generations[generation+1].count += 1;
for (i = 0; i <= generation; i++)
gcstate->generations[i].count = 0;
**//这是分代收集的关键:收集第N代时,会同时收集所有更年轻的代(0到N-1代)。**
/* merge younger generations with one we are currently collecting */
for (i = 0; i < generation; i++) {
gc_list_merge(GEN_HEAD(gcstate, i), GEN_HEAD(gcstate, generation));
}
**//young: 指向当前正在收集的代
//old: 指向下一个更老的代(或在特殊情况下指向当前代)**
/* handy references */
young = GEN_HEAD(gcstate, generation);
if (generation < NUM_GENERATIONS-1)
old = GEN_HEAD(gcstate, generation+1);
else
old = young;
validate_list(old, collecting_clear_unreachable_clear);
**//将不可达的对象封装到unreachable链表里,可达对象保留在young链表中,分离不可达对象(move_unreachable): 将`gc_refs`为0的对象移到不可达链表,大于0的对象留在可达链表。**
deduce_unreachable(young, &unreachable);
untrack_tuples(young);
/* Move reachable objects to next generation. */
if (young != old) {
if (generation == NUM_GENERATIONS - 2) {
gcstate->long_lived_pending += gc_list_size(young);
}
gc_list_merge(young, old);
}
else {
/* We only un-track dicts in full collections, to avoid quadratic
dict build-up. See issue #14775. */
untrack_dicts(young);
gcstate->long_lived_pending = 0;
gcstate->long_lived_total = gc_list_size(young);
}
**//创建一个空的链表用于存放有终结器的对象
//这个列表将包含所有不能立即删除的"问题"对象**
/* All objects in unreachable are trash, but objects reachable from
* legacy finalizers (e.g. tp_del) can't safely be deleted.
*/
gc_list_init(&finalizers);
// NEXT_MASK_UNREACHABLE is cleared here.
// After move_legacy_finalizers(), unreachable is normal list.
// 从unreachable列表中找出所有有遗留终结器的对象,移动到finalizers列表
//具体过程:
// 遍历unreachable列表中的每个对象
// 检查对象是否有__del__方法或tp_del函数
// 如果有,将该对象从unreachable移动到finalizers
// 同时清除对象的NEXT_MASK_UNREACHABLE标记
move_legacy_finalizers(&unreachable, &finalizers);
**//找出从终结器对象可达的其他对象,也移动到finalizers列表**
/* finalizers contains the unreachable objects with a legacy finalizer;
* unreachable objects reachable *from* those are also uncollectable,
* and we move those into the finalizers list too.
*/
move_legacy_finalizer_reachable(&finalizers);
validate_list(&finalizers, collecting_clear_unreachable_clear);
validate_list(&unreachable, collecting_set_unreachable_clear);
/* Print debugging information. */
if (gcstate->debug & DEBUG_COLLECTABLE) {
for (gc = GC_NEXT(&unreachable); gc != &unreachable; gc = GC_NEXT(gc)) {
debug_cycle("collectable", FROM_GC(gc));
}
}
**//清理弱引用并调用相关回调函数。**
/* Clear weakrefs and invoke callbacks as necessary. */
m += handle_weakrefs(&unreachable, old);
validate_list(old, collecting_clear_unreachable_clear);
validate_list(&unreachable, collecting_set_unreachable_clear);
**//调用对象的tp_finalize方法**
/* Call tp_finalize on objects which have one. */
finalize_garbage(tstate, &unreachable);
/* Handle any objects that may have resurrected after the call
* to 'finalize_garbage' and continue the collection with the
* objects that are still unreachable */
PyGC_Head final_unreachable;
handle_resurrected_objects(&unreachable, &final_unreachable, old);
/* Call tp_clear on objects in the final_unreachable set. This will cause
* the reference cycles to be broken. It may also cause some objects
* in finalizers to be freed.
*/
m += gc_list_size(&final_unreachable);
delete_garbage(tstate, gcstate, &final_unreachable, old);
/* Collect statistics on uncollectable objects found and print
* debugging information. */
for (gc = GC_NEXT(&finalizers); gc != &finalizers; gc = GC_NEXT(gc)) {
n++;
if (gcstate->debug & DEBUG_UNCOLLECTABLE)
debug_cycle("uncollectable", FROM_GC(gc));
}
if (gcstate->debug & DEBUG_STATS) {
double d = _PyTime_AsSecondsDouble(_PyTime_GetPerfCounter() - t1);
PySys_WriteStderr(
"gc: done, %zd unreachable, %zd uncollectable, %.4fs elapsed\n",
n+m, n, d);
}
/* Append instances in the uncollectable set to a Python
* reachable list of garbage. The programmer has to deal with
* this if they insist on creating this type of structure.
*/
handle_legacy_finalizers(tstate, gcstate, &finalizers, old);
validate_list(old, collecting_clear_unreachable_clear);
/* Clear free list only during the collection of the highest
* generation */
if (generation == NUM_GENERATIONS-1) {
clear_freelists(tstate->interp);
}
if (_PyErr_Occurred(tstate)) {
if (nofail) {
_PyErr_Clear(tstate);
}
else {
_PyErr_WriteUnraisableMsg("in garbage collection", NULL);
}
}
/* Update stats */
if (n_collected) {
*n_collected = m;
}
if (n_uncollectable) {
*n_uncollectable = n;
}
struct gc_generation_stats *stats = &gcstate->generation_stats[generation];
stats->collections++;
stats->collected += m;
stats->uncollectable += n;
if (PyDTrace_GC_DONE_ENABLED()) {
PyDTrace_GC_DONE(n + m);
}
assert(!_PyErr_Occurred(tstate));
return n + m;
}
finalize_garbage(PyThreadState *tstate, PyGC_Head *collectable)
{
destructor finalize;
PyGC_Head seen;
/* While we're going through the loop, `finalize(op)` may cause op, or
* other objects, to be reclaimed via refcounts falling to zero. So
* there's little we can rely on about the structure of the input
* `collectable` list across iterations. For safety, we always take the
* first object in that list and move it to a temporary `seen` list.
* If objects vanish from the `collectable` and `seen` lists we don't
* care.
*/
gc_list_init(&seen);
while (!gc_list_is_empty(collectable)) {
PyGC_Head *gc = GC_NEXT(collectable);
PyObject *op = FROM_GC(gc);
gc_list_move(gc, &seen);
if (!_PyGCHead_FINALIZED(gc) &&
(finalize = Py_TYPE(op)->tp_finalize) != NULL) {
_PyGCHead_SET_FINALIZED(gc);
Py_INCREF(op);
finalize(op);
assert(!_PyErr_Occurred(tstate));
Py_DECREF(op);
}
}
gc_list_merge(&seen, collectable);
}
(Objects/typeobject.c)
FLSLOT(__init__, tp_init, slot_tp_init, (wrapperfunc)(void(*)(void))wrap_init,
"__init__($self, /, *args, **kwargs)\n--\n\n"
"Initialize self. See help(type(self)) for accurate signature.",
PyWrapperFlag_KEYWORDS),
TPSLOT(__new__, tp_new, slot_tp_new, NULL,
"__new__(type, /, *args, **kwargs)\n--\n\n"
"Create and return new object. See help(type) for accurate signature."),
**TPSLOT(__del__, tp_finalize, slot_tp_finalize, (wrapperfunc)wrap_del, ""),**
BUFSLOT(__buffer__, bf_getbuffer, slot_bf_getbuffer, wrap_buffer,
"__buffer__($self, flags, /)\n--\n\n"
"Return a buffer object that exposes the underlying memory of the object."),
BUFSLOT(__release_buffer__, bf_releasebuffer, slot_bf_releasebuffer, wrap_releasebuffer,
"__release_buffer__($self, buffer, /)\n--\n\n"
"Release the buffer object that exposes the underlying memory of the object."),
......
static void
slot_tp_finalize(PyObject *self)
{
int unbound;
PyObject *del, *res;
/* Save the current exception, if any. */
PyObject *exc = PyErr_GetRaisedException();
/* Execute __del__ method, if any. */
del = lookup_maybe_method(self, &_Py_ID(__del__), &unbound);
if (del != NULL) {
res = call_unbound_noarg(unbound, del, self);
if (res == NULL)
PyErr_WriteUnraisable(del);
else
Py_DECREF(res);
Py_DECREF(del);
}
/* Restore the saved exception. */
PyErr_SetRaisedException(exc);
}
// 调用del方法
lookup_maybe_method(PyObject *self, PyObject *attr, int *unbound)
{
PyObject *res = _PyType_Lookup(Py_TYPE(self), attr);
if (res == NULL) {
return NULL;
}
if (_PyType_HasFeature(Py_TYPE(res), Py_TPFLAGS_METHOD_DESCRIPTOR)) {
/* Avoid temporary PyMethodObject */
*unbound = 1;
Py_INCREF(res);
}
else {
*unbound = 0;
descrgetfunc f = Py_TYPE(res)->tp_descr_get;
if (f == NULL) {
Py_INCREF(res);
}
else {
res = f(res, self, (PyObject *)(Py_TYPE(self)));
}
}
return res;
}
(Objects/typeobject.c)
FLSLOT(__init__, tp_init, slot_tp_init, (wrapperfunc)(void(*)(void))wrap_init,
"__init__($self, /, *args, **kwargs)\n--\n\n"
"Initialize self. See help(type(self)) for accurate signature.",
PyWrapperFlag_KEYWORDS),
TPSLOT(__new__, tp_new, slot_tp_new, NULL,
"__new__(type, /, *args, **kwargs)\n--\n\n"
"Create and return new object. See help(type) for accurate signature."),
**TPSLOT(__del__, tp_finalize, slot_tp_finalize, (wrapperfunc)wrap_del, ""),**
BUFSLOT(__buffer__, bf_getbuffer, slot_bf_getbuffer, wrap_buffer,
"__buffer__($self, flags, /)\n--\n\n"
"Return a buffer object that exposes the underlying memory of the object."),
BUFSLOT(__release_buffer__, bf_releasebuffer, slot_bf_releasebuffer, wrap_releasebuffer,
"__release_buffer__($self, buffer, /)\n--\n\n"
"Release the buffer object that exposes the underlying memory of the object."),
......
static void
slot_tp_finalize(PyObject *self)
{
int unbound;
PyObject *del, *res;
/* Save the current exception, if any. */
PyObject *exc = PyErr_GetRaisedException();
/* Execute __del__ method, if any. */
del = lookup_maybe_method(self, &_Py_ID(__del__), &unbound);
if (del != NULL) {
res = call_unbound_noarg(unbound, del, self);
if (res == NULL)
PyErr_WriteUnraisable(del);
else
Py_DECREF(res);
Py_DECREF(del);
}
/* Restore the saved exception. */
PyErr_SetRaisedException(exc);
}
// 调用del方法
lookup_maybe_method(PyObject *self, PyObject *attr, int *unbound)
{
PyObject *res = _PyType_Lookup(Py_TYPE(self), attr);
if (res == NULL) {
return NULL;
}
if (_PyType_HasFeature(Py_TYPE(res), Py_TPFLAGS_METHOD_DESCRIPTOR)) {
/* Avoid temporary PyMethodObject */
*unbound = 1;
Py_INCREF(res);
}
else {
*unbound = 0;
descrgetfunc f = Py_TYPE(res)->tp_descr_get;
if (f == NULL) {
Py_INCREF(res);
}
else {
res = f(res, self, (PyObject *)(Py_TYPE(self)));
}
}
return res;
}
update_refs(PyGC_Head *containers)
{
PyGC_Head *next;
PyGC_Head *gc = GC_NEXT(containers);
while (gc != containers) {
next = GC_NEXT(gc);
/* Move any object that might have become immortal to the
* permanent generation as the reference count is not accurately
* reflecting the actual number of live references to this object
*/
if (_Py_IsImmortal(FROM_GC(gc))) {
gc_list_move(gc, &get_gc_state()->permanent_generation.head);
gc = next;
continue;
}
gc_reset_refs(gc, Py_REFCNT(FROM_GC(gc)));
/* Python's cyclic gc should never see an incoming refcount
* of 0: if something decref'ed to 0, it should have been
* deallocated immediately at that time.
* Possible cause (if the assert triggers): a tp_dealloc
* routine left a gc-aware object tracked during its teardown
* phase, and did something-- or allowed something to happen --
* that called back into Python. gc can trigger then, and may
* see the still-tracked dying object. Before this assert
* was added, such mistakes went on to allow gc to try to
* delete the object again. In a debug build, that caused
* a mysterious segfault, when _Py_ForgetReference tried
* to remove the object from the doubly-linked list of all
* objects a second time. In a release build, an actual
* double deallocation occurred, which leads to corruption
* of the allocator's internal bookkeeping pointers. That's
* so serious that maybe this should be a release-build
* check instead of an assert?
*/
_PyObject_ASSERT(FROM_GC(gc), gc_get_refs(gc) != 0);
gc = next;
}
}
将每个对象的 gc_refs 初始化为其 ob_refcnt(原始引用计数)。ob_refcnt 包含了来自 所有来源 的引用,包括:
栈上的变量(函数局部变量)
全局/静态变量
其他代(非当前回收代)的对象
非容器对象(如整数、字符串等)
这些来源共同构成了 GC 的根。
subtract_refs(base):
遍历当前代(base 链表)的对象,对每个对象引用的 其他同代对象,减少其 gc_refs。这相当于减去了 同代对象间的内部引用。
结果:
若对象最终 gc_refs > 0:表示存在 来自根(外部)的引用。
若 gc_refs = 0:对象仅被同代对象引用(形成孤岛),判定为不可达。
graph TD
A[开始回收] --> B[合并年轻代]
B --> C[标记可达对象]
C --> D[分离不可达对象]
D --> E[处理终结器对象]
E --> F[处理弱引用]
F --> G[执行__del__方法]
G --> H[检查复活对象]
H --> I[回收最终不可达对象]
I --> J[处理不可回收对象]
J --> K[更新统计信息]
K --> L[结束]
public class CustomCard_ReflectProxy : ComponentProxy {
override fun createInstance(args: Map<String, Any?>): Any {
return CustomCard(
title = args["title"] as String
)
}
override val descriptor = ComponentDescriptor(
name = "CustomCard",
params = listOf(
ParameterDescriptor("title", String::class)
)
)
}
组件注册表
object ComposeComponentRegistry {
private val registry = ConcurrentHashMap<String, ComponentProxy>()
fun register(proxy: ComponentProxy) {
registry[proxy.descriptor.name] = proxy
}
fun createComponent(name: String, args: Map<String, Any?>): Any {
return registry[name]?.createInstance(args)
?: throw ComponentNotFoundException(name)
}
}
object DemoFunctionExpress {
/** * result =10 * result2 =10 * index = 5 */
fun test2(index: Int, item: String): Int {
val a = 2
val b = 2 + index
return a * b
}
}
object DemoFunctionExpress {
/** * result =10 * result2 =10 * index = 5 */
fun test2(index: Int, item: String): Int {
val a = 2
val b = 2 + index
return a * b
}
}
输出结果
val test2 = runtime.invoke("test2", mutableListOf(5,"a"))
System.out.println("动态化引擎输出结果:" + test2)
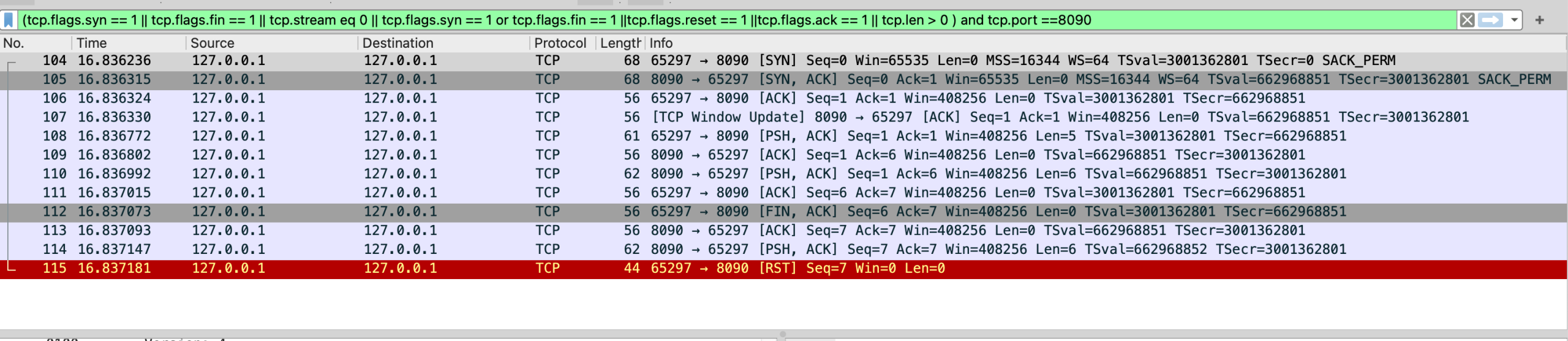

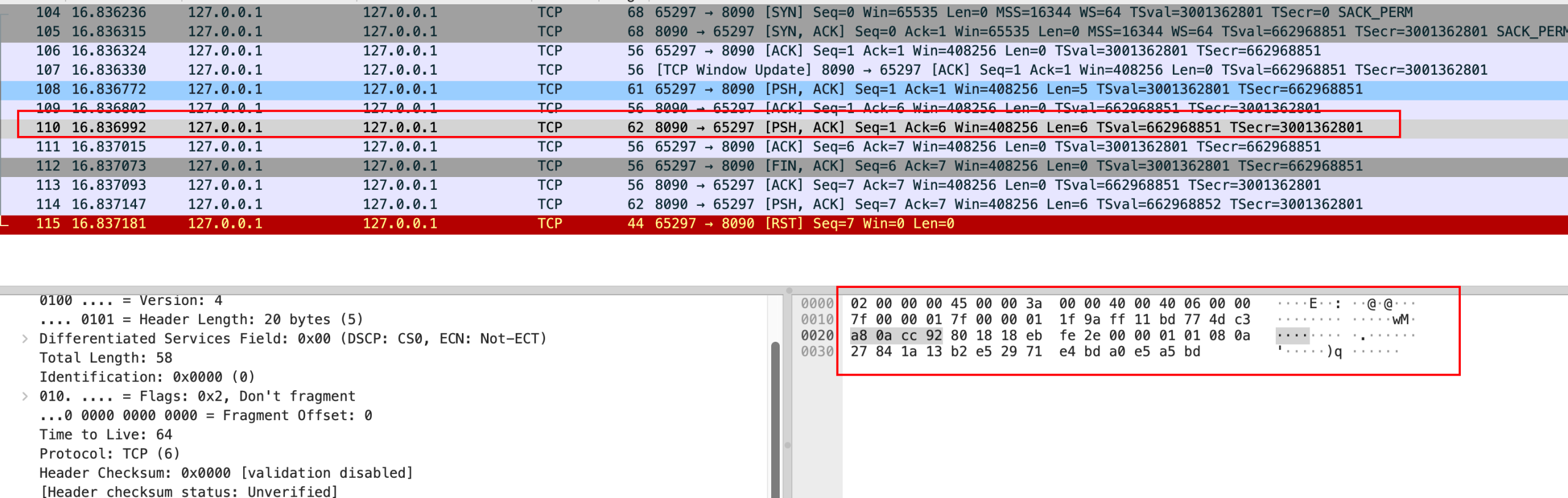
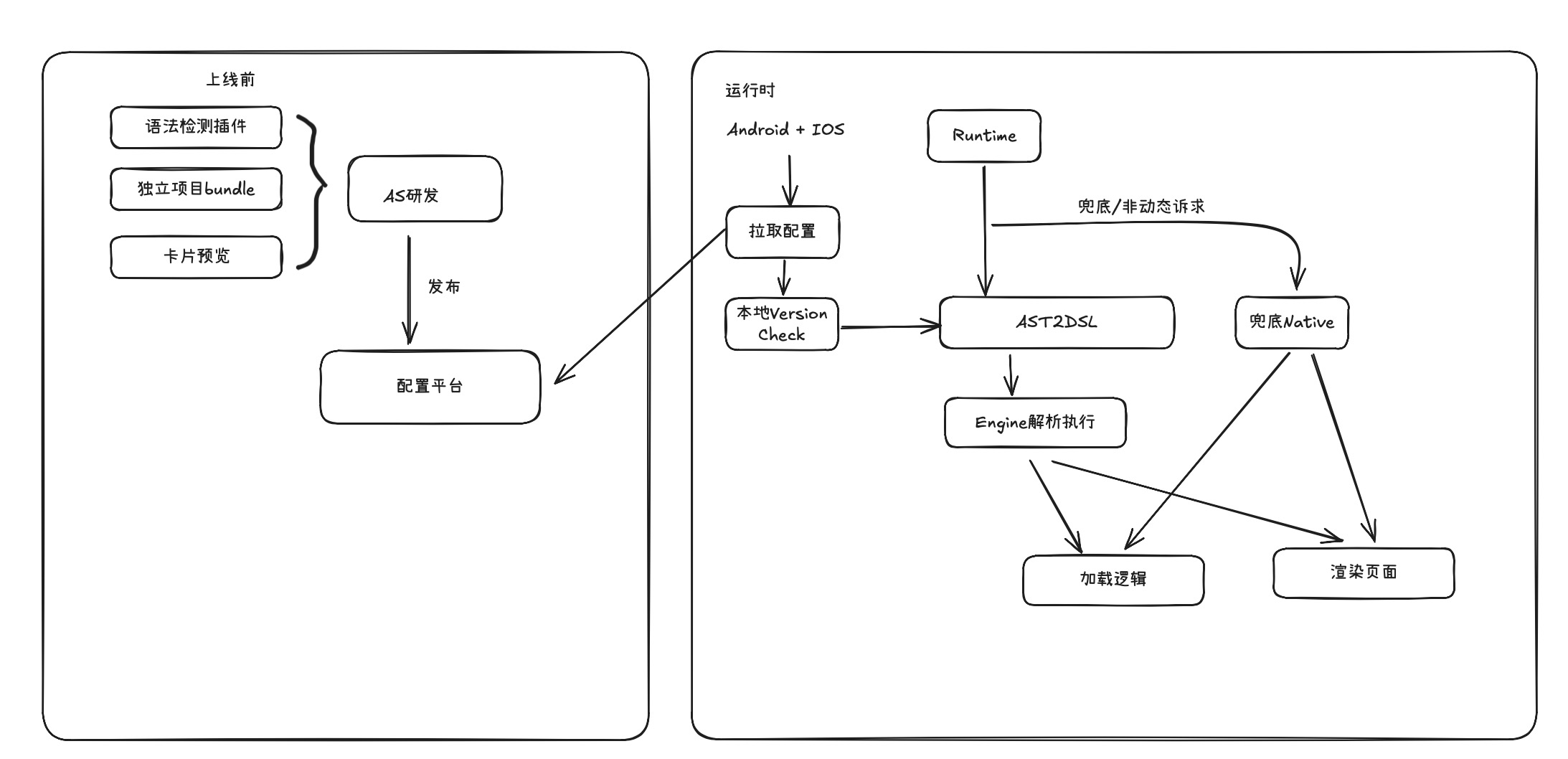
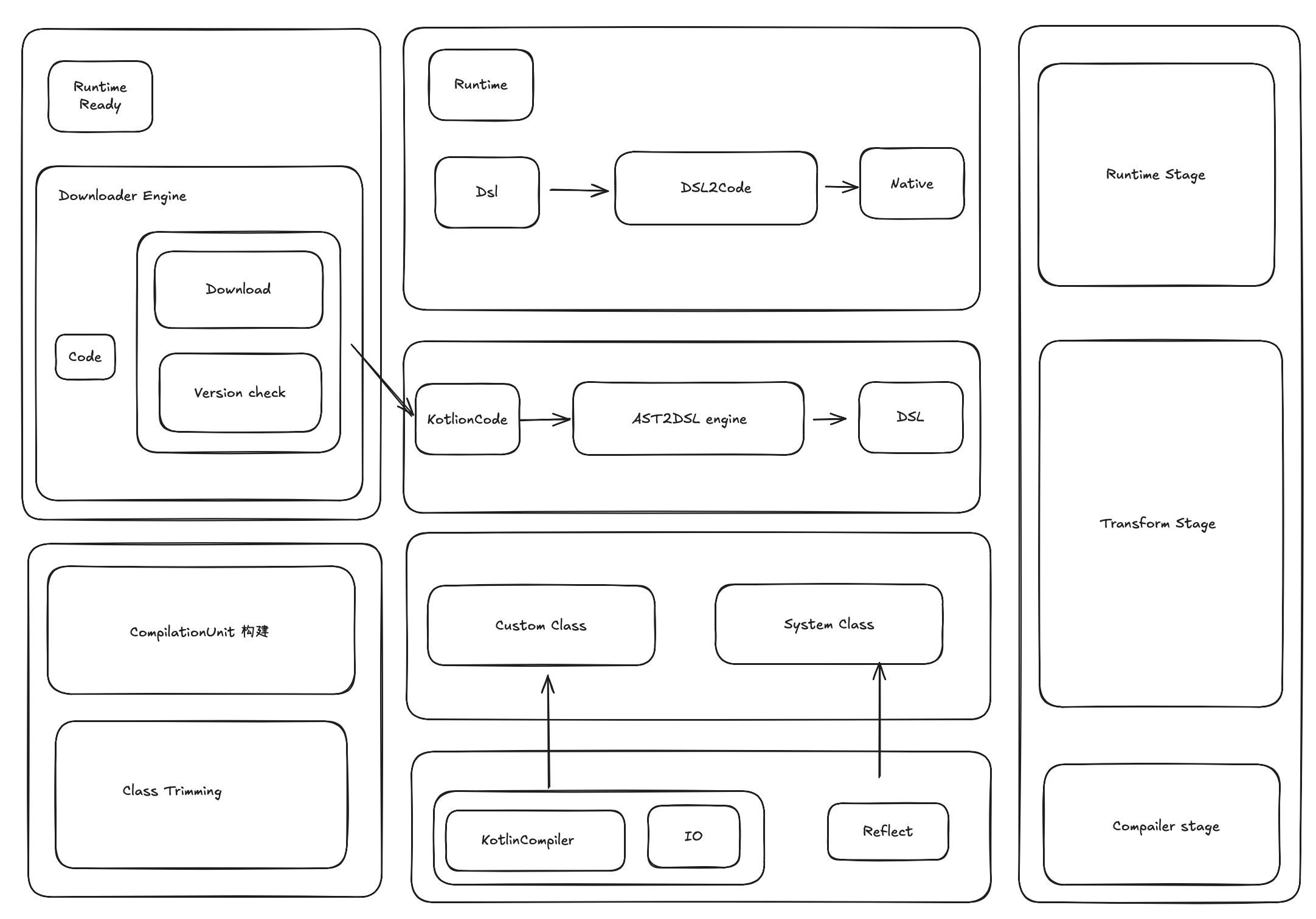 最下面的部分是编译依赖
最下面的部分是编译依赖

 沪ICP备2025124802号-1
沪ICP备2025124802号-1